Eine Vektordatenbank ist eine Sammlung von Daten, in der jedes Datum in Form eines (digitalen) Vektors gespeichert wird. Ein Vektor stellt ein Objekt oder eine Entität wie ein Bild, eine Person, einen Ort usw. in einem abstrakten N-dimensionalen Raum dar.
Vektoren, wie sie im vorheriges Kapitelsind entscheidend für die Identifizierung der Art und Weise, wie Entitäten miteinander verbunden sind, und können verwendet werden, um ihre semantische Ähnlichkeit zu finden. Dies kann auf verschiedene Weise für die Suchmaschinenoptimierung angewendet werden - etwa durch die Gruppierung von ähnlichen Schlüsselwörtern oder Inhalten (mithilfe von kNN).
In diesem Artikel werden wir einige Möglichkeiten kennenlernen, wie Sie KI auf die Suchmaschinenoptimierung anwenden können, z. B. indem Sie semantisch ähnliche Inhalte für die interne Verlinkung finden. Dies kann Ihnen helfen, Ihre Inhaltsstrategie in einer Zeit zu verfeinern, in der Suchmaschinen immer häufiger zu stützen sich zunehmend auf LLMs.
Sie können auch einen früheren Artikel dieser Reihe darüber lesen, wie man die Kannibalisierung von Schlüsselwörtern mithilfe der Textintegration von OpenAI.
Tauchen wir hier ein und beginnen wir mit dem Aufbau der Grundlage für unser Werkzeug.
Vektordatenbanken verstehen
Wenn Sie Tausende von Artikeln haben und die ähnlichste semantische Ähnlichkeit für Ihre Zielanfrage finden wollen, können Sie nicht einfach on-the-fly für alle Artikel Vektor-Embeddings erstellen, um sie zu vergleichen, da dies sehr ineffizient ist.
Damit dies möglich ist, müsste man die Vektor-Embeddings einmalig generieren und in einer Datenbank speichern, die man nach dem nächstgelegenen Artikel abfragen kann.
Das machen Vektordatenbanken: Das sind besondere Arten von Datenbanken, die Einbettungen (Vektoren) speichern.
Wenn Sie die Datenbank abfragen, führen sie im Gegensatz zu herkömmlichen Datenbanken Folgendes aus cosinus similarity match und gibt die Vektoren (in diesem Fall die Artikel) zurück, die einem anderen abgefragten Vektor (in diesem Fall einem Schlüsselwort) am nächsten liegen.
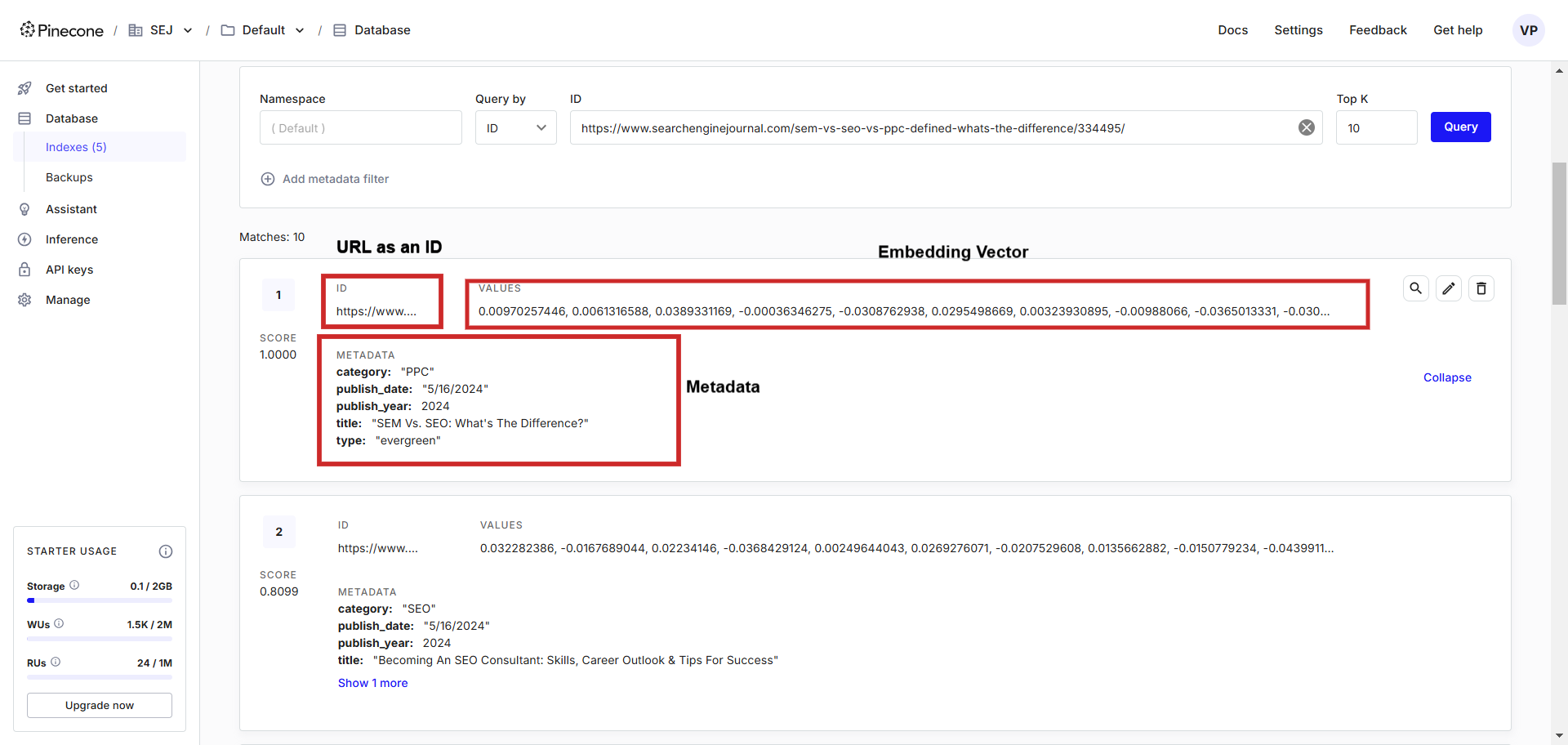
So sieht es aus:
In der Vektordatenbank sehen Sie die Vektoren mit den gespeicherten Metadaten, die wir leicht befragen mithilfe einer Programmiersprache unserer Wahl.
In diesem Artikel verwenden wir Kiefernzapfen aufgrund seiner leichten Verständlichkeit und einfachen Handhabung, aber es gibt auch andere Anbieter wie z. B. Chroma, BigQueryoder Qdrant die Sie sich ansehen können.
Kommen wir zum Kern der Sache.
1. Erstellen einer Vektordatenbank
Zunächst legen Sie ein Konto bei Pinecone an und erstellen einen Index mit einer Konfiguration von "text-embedding-ada-002" mit "Kosinus" als Metrik zur Messung der Vektorentfernung. Sie können dem Index einen beliebigen Namen geben, wir nennen ihnartikel-index-all-ada'.
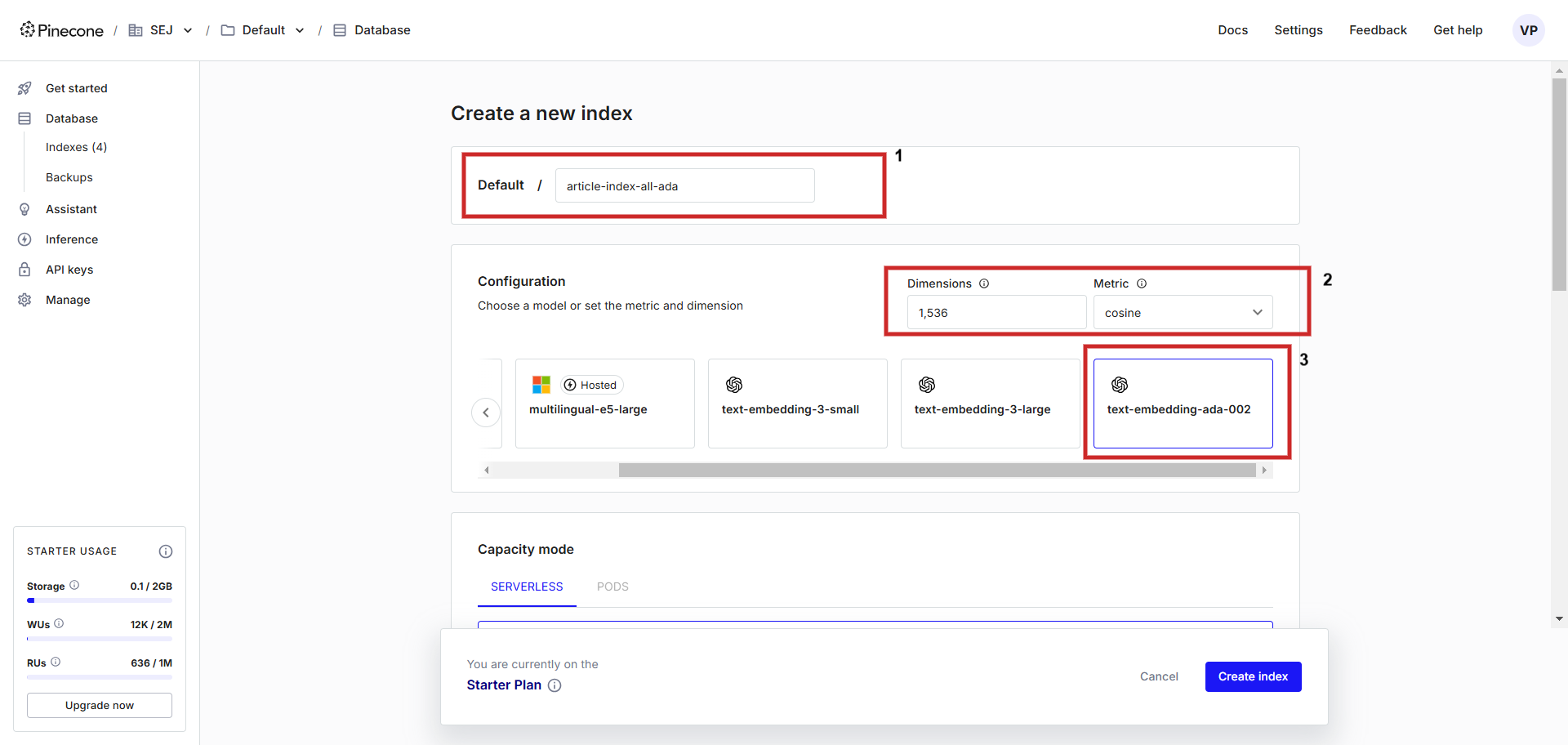 Erstellung einer Vektordatenbank.
Erstellung einer Vektordatenbank.Diese Hilfsoberfläche dient nur dazu, Sie bei der Konfiguration zu unterstützen. Wenn Sie die Integration von Vertex AI-Vektoren speichern möchten, müssen Sie 'dimensions' auf 768 im Konfigurationsbildschirm an, um der Standarddimensionalität zu entsprechen, und Sie können Vertex AI-Textvektoren speichern (Sie können einen Dimensionswert von 1 à 768 um Speicherplatz zu sparen).
In diesem Artikel lernen wir, wie man die OpenAi-Funktionen 'text-embedding-ada-002' und 'text-embedding-ada-002' verwendet. Vertex AI von Google Vorlagen "text-embedding-005".
Sobald sie erstellt wurde, benötigen wir einen API-Schlüssel, damit wir uns über die Host-URL der Vektordatenbank mit der Datenbank verbinden können.
API-Schlüssel generieren
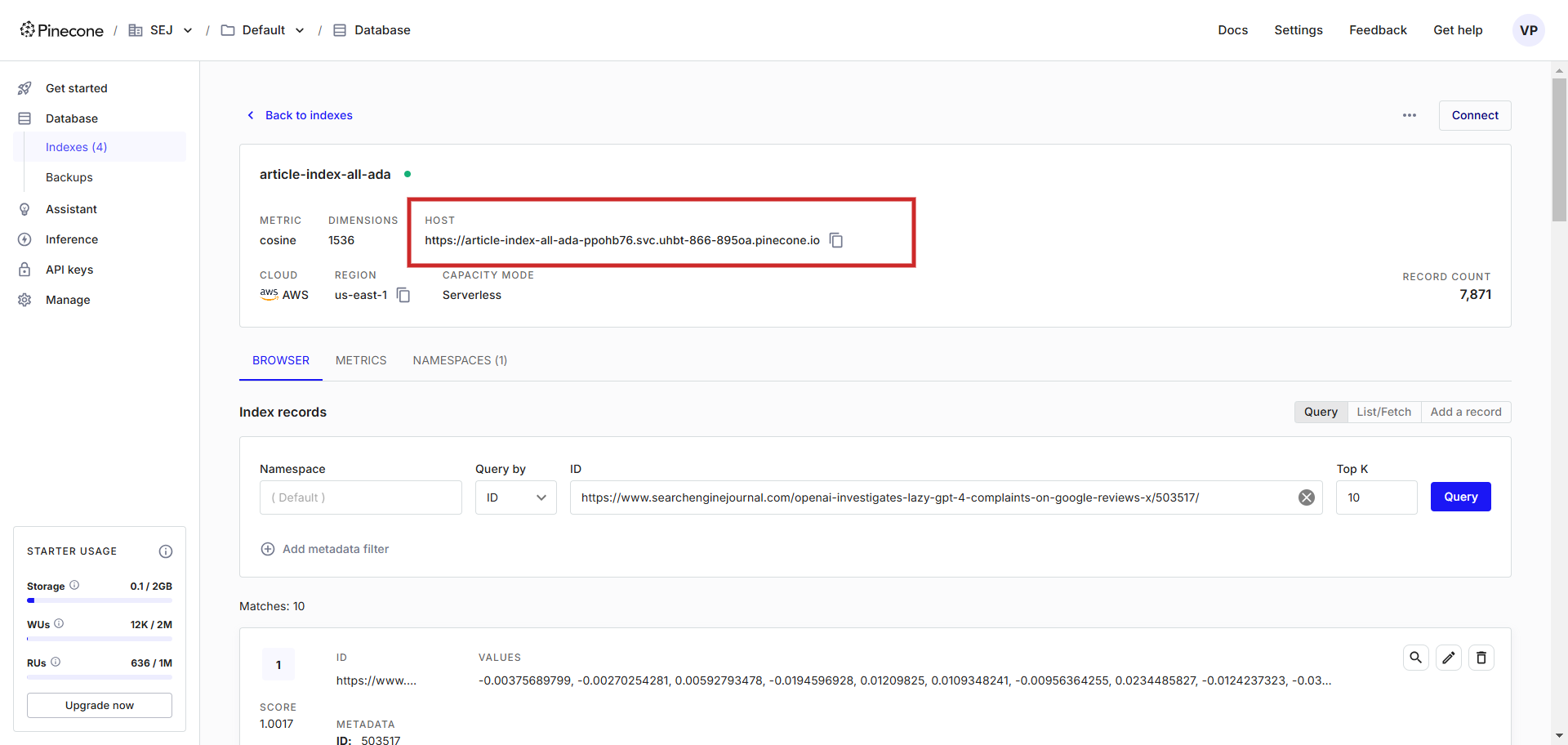
URL des Hosts der Vektordatenbank
Dann müssen Sie mit Jupyter Notebook. Wenn Sie es nicht installiert haben, folgen Sie den folgenden Anweisungen dieser Leitfaden um es zu installieren und führen Sie dann diesen Befehl (unten) im Terminal Ihres PCs aus, um alle notwendigen Pakete zu installieren.
pip install openai google-cloud-aiplatform google-auth pandas pinecone-client tabulate ipython numpyUnd denken Sie daran, dass ChatGPT sehr hilfreich ist, wenn Sie beim Codieren auf Probleme stoßen!
2. Exportieren Sie Ihre Artikel aus Ihrem CMS
Als Nächstes müssen wir eine CSV-Exportdatei der Artikel aus Ihrem CMS vorbereiten. Wenn Sie WordPress verwenden, können Sie dafür ein Plugin verwenden. benutzerdefinierte Exporte.
Da unser Endziel der Aufbau eines internen Verknüpfungswerkzeugs ist, müssen wir entscheiden, welche Daten als Metadaten in die Vektordatenbank übertragen werden sollen. Im Wesentlichen fungiert die metadatenbasierte Filterung als eine zusätzliche Ebene der Suchorientierung, indem sie diese an der allgemeinen Ausrichtung der Vektordatenbank ausrichtet. RAG-Rahmen indem sie externes Wissen einbeziehen, was zur Verbesserung der Qualität der Forschung beiträgt.
Wenn wir beispielsweise einen Artikel über "PPC" bearbeiten und einen Link auf den Ausdruck "Keyword Research" einfügen möchten, können wir in unserem Tool angeben, dass "Category=PPC". Oder wir möchten einen Link zum Ausdruck "Neuestes Google-Update" erstellen und den Treffer nur auf aktuelle Artikel beschränken, die "Type" verwenden und in diesem Jahr veröffentlicht wurden.
In unserem Fall werden wir exportieren :
- Titel.
Kategorie. - Typ.
- Datum der Veröffentlichung.
- Jahr der Veröffentlichung.
- Permalink.
- Meta Description.
- Inhalt.
Um die besten Ergebnisse zu erzielen, verknüpfen wir die Felder Titel und Meta-Beschreibung, da sie die beste Darstellung des Artikels sind, die wir vektorisieren können, und sich ideal für die Einbindung und interne Verlinkung eignen.
Die Verwendung des gesamten Inhalts des Artikels für die Integration kann die Genauigkeit verringern und die Relevanz der Vektoren verwässern.
Das liegt daran, dass eine einzelne große Einbettung versucht, mehrere Themen, die der Artikel abdeckt, gleichzeitig darzustellen, was zu einer weniger zielgerichteten und relevanten Darstellung führt. Gruppierung Strategien (Aufteilung des Artikels in natürliche Rubriken oder semantisch bedeutsame Segmente) angewendet werden müssen, ist jedoch nicht Gegenstand dieses Artikels.
Hier ist der Artikel beispiel für eine exportdatei die Sie herunterladen und für unseren Beispielcode unten verwenden können.
2. Einfügen von OpenAi-Textkodierungen in die Vektordatenbank
Angenommen, Sie haben bereits eine Datenbank API-Schlüssel OpenAIDieser Code erzeugt aus dem Text vektorbasierte Einbettungen und fügt sie in die Vektordatenbank von Pinecone ein.
import pandas as pd
from openai import OpenAI
from pinecone import Pinecone
from IPython.display import clear_output
# Setzen Sie Ihre OpenAI- und Pinecone-API-Schlüssel ein.
openai_client = OpenAI(api_key='YOUR_OPENAI_API_KEY') # Instantiate OpenAI client.
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY')
# Verbindung zu einem bestehenden Pinecone-Index.
index_name = "article-index-all-ada".
index = pinecone.Index(index_name)
def generate_embeddings(text):
"""
Erzeugt eine Einbettung für den gegebenen Text mithilfe der API von OpenAI.
Gibt None zurück, wenn der Text ungültig ist oder ein Fehler auftritt.
"""
try:
if not text or not isinstance(text, str):
raise ValueError("Input text must be a non-empty string.")
result = openai_client.embeddings.create(
input=text,
model="text-embedding-ada-002"
)
clear_output(wait=True) # Ausgabe für eine frische Anzeige löschen
if hasattr(result, 'data') and len(result.data) > 0:
print("API Response:", result)
return result.data[0].embedding
else:
raise ValueError("Invalid response from the OpenAI API. No data returned.")
except ValueError as ve:
print(f "ValueError: {ve}")
return None
except Exception as e:
print(f "Ein Fehler trat bei der Generierung von Einbettungen auf: {e}")
return None
# Laden Sie Ihre Artikel aus einer CSV-Datei.
df = pd.read_csv('Sample Export File.csv')
# Process each article
for idx, row in df.iterrows():
try:
clear_output(wait=True)
content = row["Inhalt"].
vector = generate_embeddings(content)
if vector is None:
print(f "Skipping article ID {row['ID']} due to empty or invalid embedding.")
weiter
index.upsert(vectors=[
(
row['Permalink'], # Unique ID
vector, # The embedding
{
title': row['Title'],
category': row['Category'],
type': row['Type'],
publish_date': row['Publish Date'],
publish_year': row['Publish Year']]
}
)
])
except Exception as e:
clear_output(wait=True)
print(f "Fehler bei der Verarbeitung von Artikel ID {row['ID']}: {str(e)}")
print("Einbettungen werden erfolgreich in der Vektordatenbank gespeichert.")
Sie müssen eine Notebook-Datei erstellen, diese kopieren und einfügen und dann die CSV-Datei 'Sample Export File.csv' in denselben Ordner hochladen.
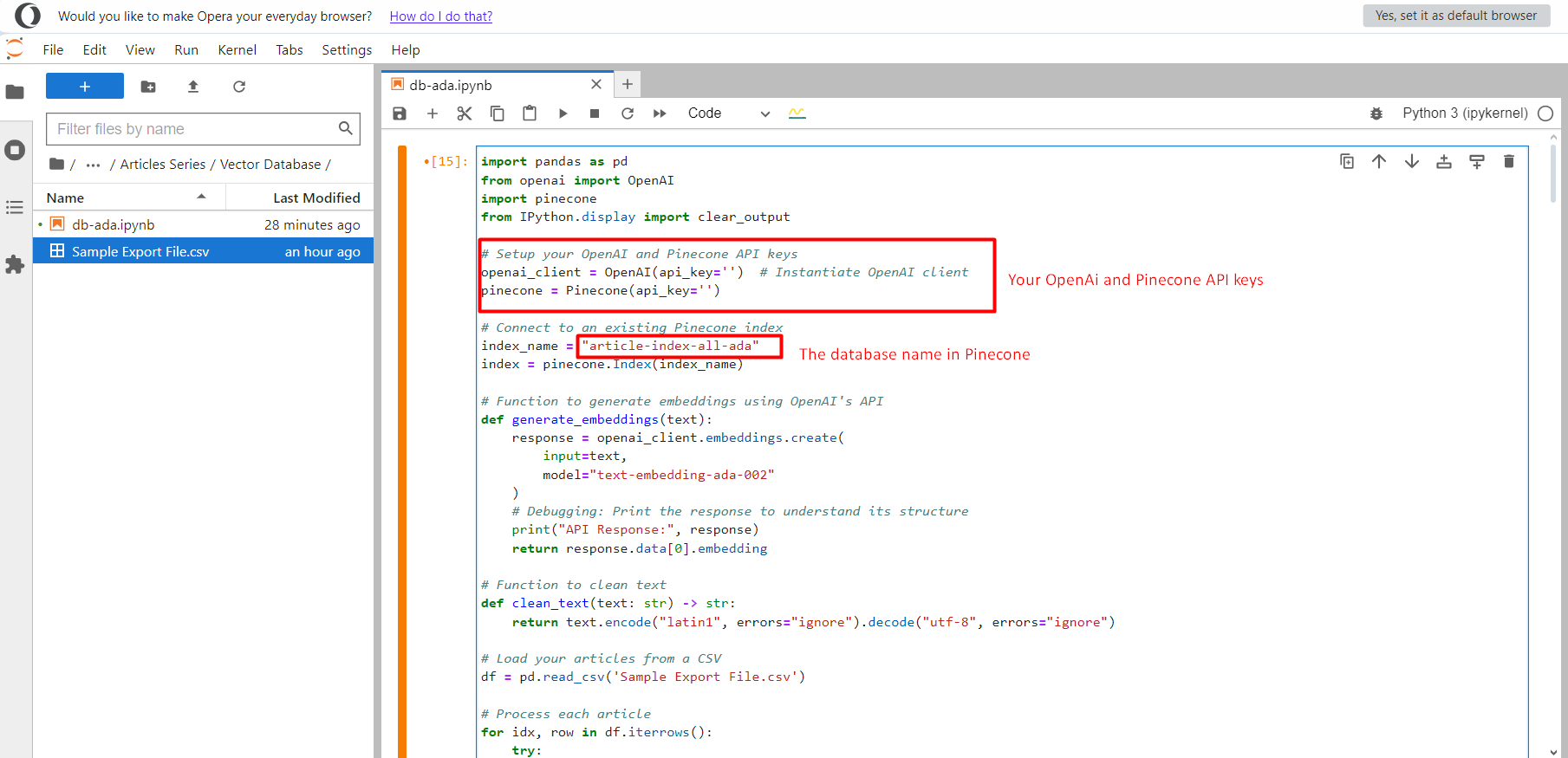 Jupyter-Projekt.
Jupyter-Projekt.Sobald dies geschehen ist, klicken Sie auf die Schaltfläche Run und es beginnt damit, alle Vektoren für die Texteinbindung in den Index zu schieben. artikel-index-all-ada die wir im ersten Schritt erstellt haben.
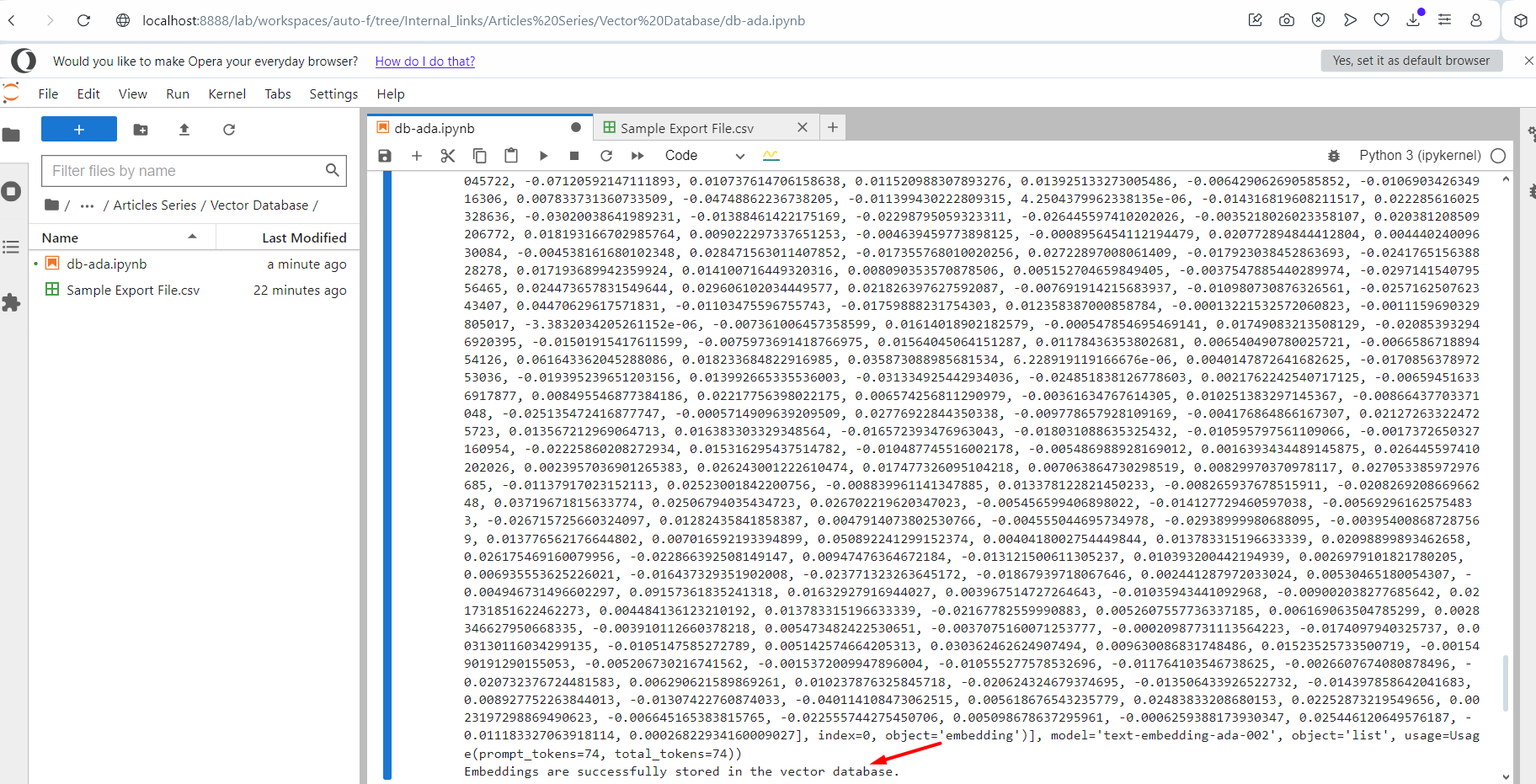 Ausführung des Skripts.
Ausführung des Skripts.Sie werden den Text des Ausgabeprotokolls der Integrationsvektoren sehen. Wenn das Skript fertig ist, zeigt es am Ende eine Meldung an, die besagt, dass es erfolgreich ausgeführt wurde. Überprüfen Sie nun Ihren Index in der Pinecone und Sie sehen Ihren befinden sich dort.
3. Einen Artikel zu einem Stichwort finden
Versuchen wir nun, einen Artikel zu finden, der dem Stichwort entspricht.
Erstellen Sie eine neue Notebookdatei und kopieren Sie diesen Code und fügen Sie ihn ein.
from openai import OpenAI
from pinecone import Pinecone
from IPython.display import clear_output
from tabulate import tabulate # Import tabulate for table formatting
# Setzen Sie Ihre OpenAI- und Pinecone-API-Schlüssel.
openai_client = OpenAI(api_key='YOUR_OPENAI_API_KEY') # Instantiate OpenAI client
pinecone = Pinecone(api_key='YOUR_OPENAI_API_KEY')
# Verbindung zu einem bestehenden Pinecone-Index.
index_name = "article-index-all-ada".
index = pinecone.Index(index_name)
# Funktion zum Erzeugen von Einbettungen mithilfe der API von OpenAI.
def generate_embeddings(text):
"""
Erzeugt eine Einbettung für einen bestimmten Text mithilfe der API von OpenAI.
"""
try:
if not text or not isinstance(text, str):
raise ValueError("Input text must be a non-empty string.")
result = openai_client.embeddings.create(
input=text,
model="text-embedding-ada-002"
)
# Debugging: Drucken Sie die Antwort aus, um ihre Struktur zu verstehen.
clear_output(wait=True)
#print("API Response:", result)
if hasattr(result, 'data') and len(result.data) > 0:
return result.data[0].embedding
else:
raise ValueError("Invalid response from the OpenAI API. No data returned.")
except ValueError as ve:
print(f "ValueError: {ve}")
return None
except Exception as e:
print(f "Ein Fehler trat bei der Generierung von Einbettungen auf: {e}")
return None
# Funktion zur Abfrage des Pinecone-Index mit Schlüsselwörtern und Metadaten
def match_keywords_to_index(keywords):
"""
Matches eine Liste von Schlüsselwörtern zum nächstgelegenen Artikel im Pinecone-Index, dynamisch gefiltert nach Metadaten.
"""
Ergebnisse = []
für keyword_pair in keywords:
try:
clear_output(wait=True)
# Extrahieren Sie das Schlüsselwort und die Kategorie aus dem Teilarray.
keyword = keyword_pair[0].
category = keyword_pair[1]
# Generiere embedding für das aktuelle keyword.
vector = generate_embeddings(keyword)
wenn vector der Wert None ist:
print(f "Skipping keyword '{keyword}' due to embedding error.")
weiter
# Query the Pinecone index for the closest vector with metadata filter.
query_results = index.query(
vector=vector, # Die Einbettung des Schlüsselworts.
top_k=1, # Nur den geschlossensten Treffer abrufen.
include_metadata=True, # Metadaten in den Ergebnissen einschließen.
filter={"category": category} # Ergebnisse dynamisch nach Metadatenkategorie filtern.
)
# Speichert den letzten Treffer.
if query_results['matches']:
closest_match = query_results['matches'][0]
results.append({
'Keyword': keyword, # The searched keyword
Kategorie': Kategorie, # Die für die Filterung verwendete Kategorie.
Match Score': f"{closest_match['score']:.2f}", # Similarity score (formatiert auf 2 Dezimalstellen).
Titel': closest_match['metadata'].get('title', 'N/A'), # Titel des Artikels.
URL': closest_match['id'] # Verwendet 'id' als URL.
})
else:
results.append({
'Keyword': keyword,
'Category': Kategorie,
Match Score': 'N/A',
Titel': 'No match found',
URL': 'N/A'
})
except Exception as e:
clear_output(wait=True)
print(f "Fehler bei der Verarbeitung des Schlüsselworts '{keyword}' mit der Kategorie '{category}': {e}")
results.append({
'Keyword': keyword,
'Category': Kategorie,
Match Score': 'Error',
Title': 'Error occurred',
URL': 'N/A'
})
return results
# Beispielverwendung: Übereinstimmungen für eine Reihe von Schlüsselwörtern und Kategorien finden
keywords = [["SEO Tools", "SEO"], ["TikTok", "TikTok"], ["SEO Consultant", "SEO"]] # Ersetze mit deinen Schlüsselwörtern und Kategorien.
matches = match_keywords_to_index(keywords)
# Zeigen Sie die Ergebnisse in einer Tabelle an.
print(tabulate(matches, headers="keys", tablefmt="fancy_grid"))
Wir versuchen, eine Übereinstimmung für diese Schlüsselwörter zu finden:
- SEO-Tools.
- TikTok.
- SEO-Berater.
Und hier ist das Ergebnis, das wir nach der Ausführung des Codes erhalten :
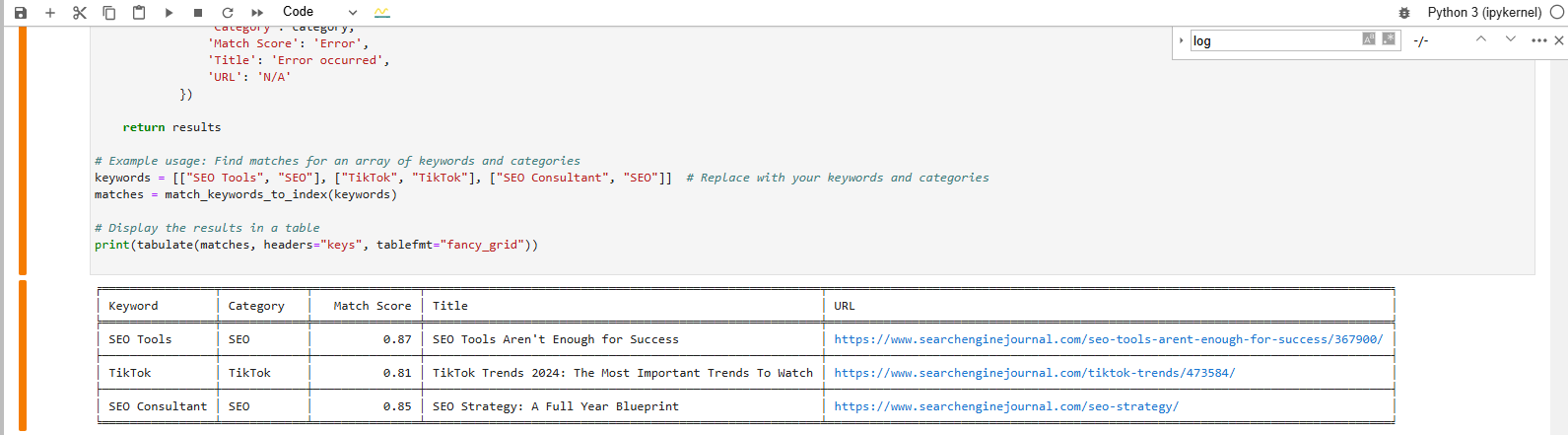 Eine Übereinstimmung für den Ausdruck des Schlüsselworts in der Vektordatenbank finden
Eine Übereinstimmung für den Ausdruck des Schlüsselworts in der Vektordatenbank findenDie formatierte Tabelle unten auf der Seite zeigt die Artikel, die unseren Schlüsselwörtern am nächsten kommen.
4. Einfügen von Google Vertex AI Textintegrationen in die Vektordatenbank
Lassen Sie uns nun das Gleiche tun, aber mit Google Vertex AI 'text-embedding-005'embedding' (Einbettung). Dieses Modell ist bemerkenswert, weil es von Google, den Behörden Vertex AI Forschungund ist speziell für die Bearbeitung von Such- und Suchanfragen-Matching-Aufgaben ausgebildet, wodurch er sich gut für unseren Anwendungsfall eignet.
Sie können sogar einen internes Suchwidget und fügen Sie es Ihrer Website hinzu.
Melden Sie sich zunächst in der Google Cloud Console und in ein Projekt erstellen. Dann vom Bildschirm aus API-Bibliothek Vertex AI API finden und aktivieren.
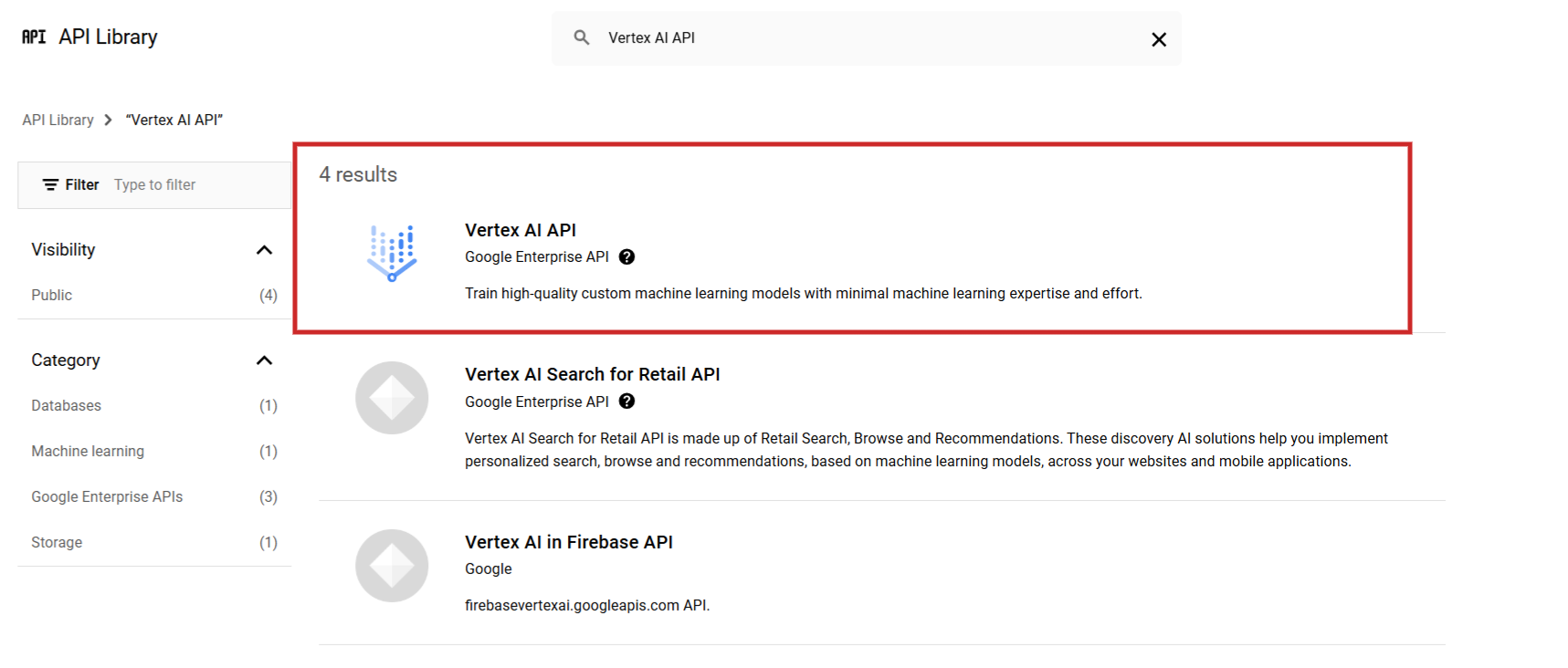 Screenshot von Google Cloud Console, Dezember 2024
Screenshot von Google Cloud Console, Dezember 2024Richten Sie Ihr Abrechnungskonto so ein, dass Sie Vertex AI auf Grundlage der Preisgestaltung nutzen können. $0.0002 für 1.000 Zeichen (und bietet 300 $ Guthaben für neue Nutzer).
Sobald Sie dies festgelegt haben, gehen Sie zu folgender Adresse API Services > Credentials erstellen Sie ein Dienstkonto, generieren Sie einen Schlüssel und laden Sie ihn im JSON-Format hoch.
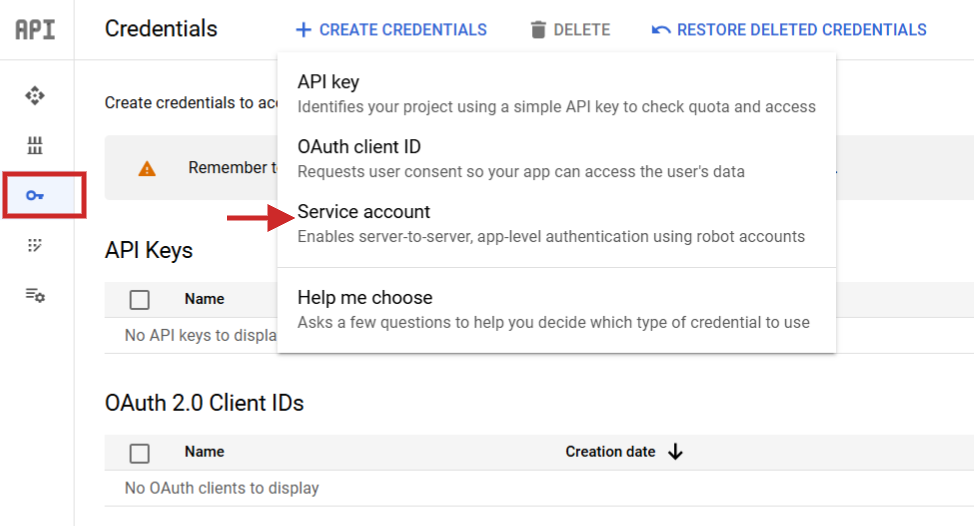
Schritt 1: Erstellen eines Kontos Service a
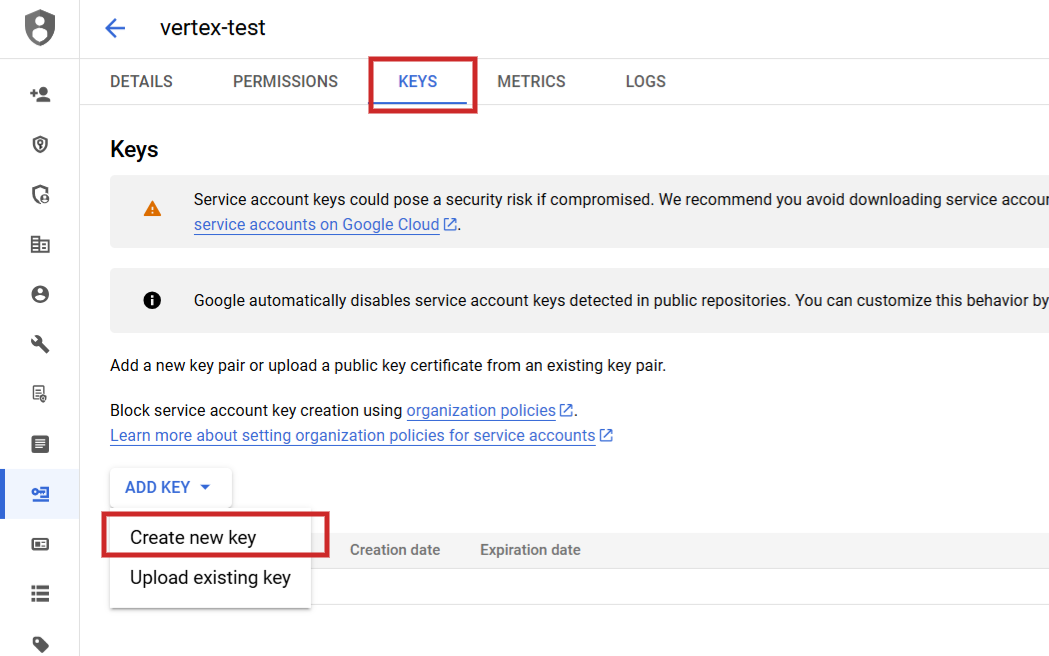
Schritt 2: Hinzufügen eines neuen Schlüssels auf der Registerkarte Schlüssel des Dienstkontos
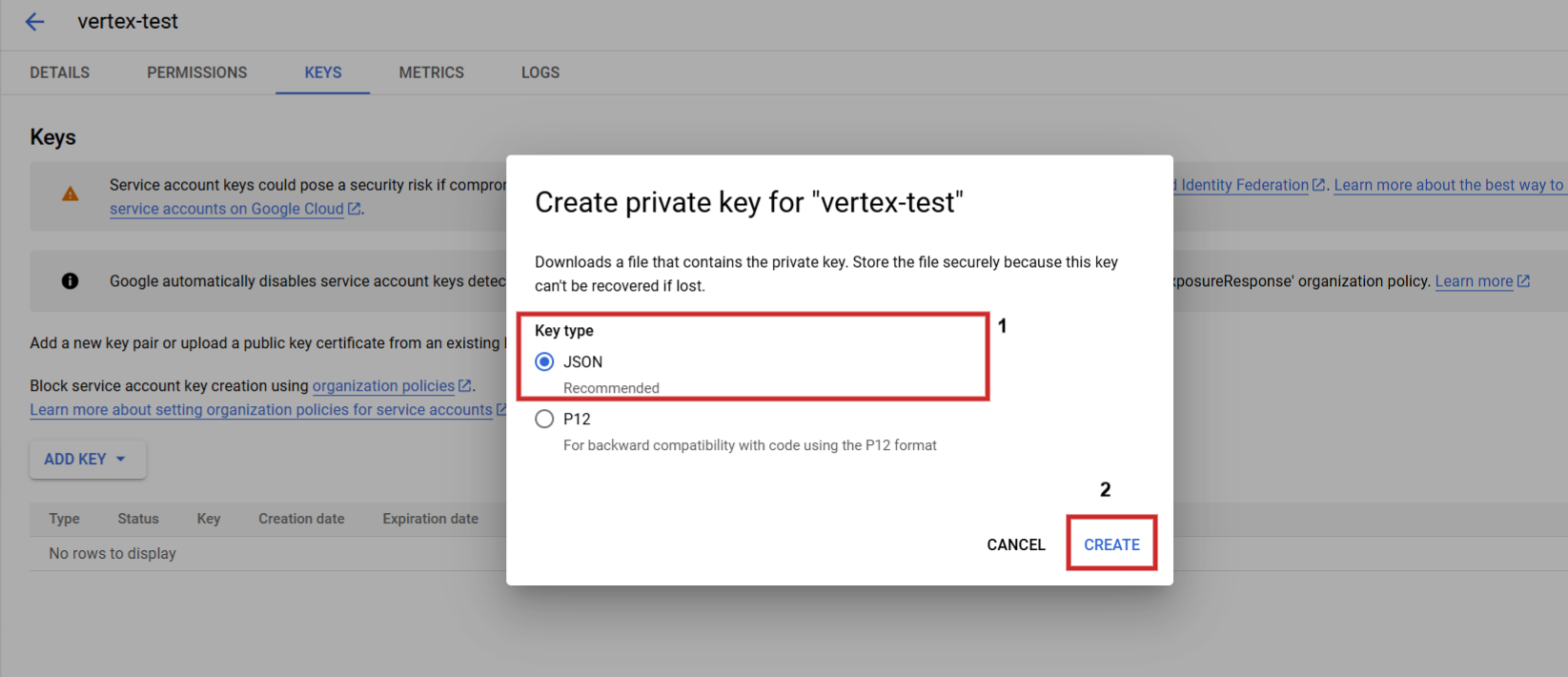
Schritt 3: Erstellen eines JSON-Schlüssels
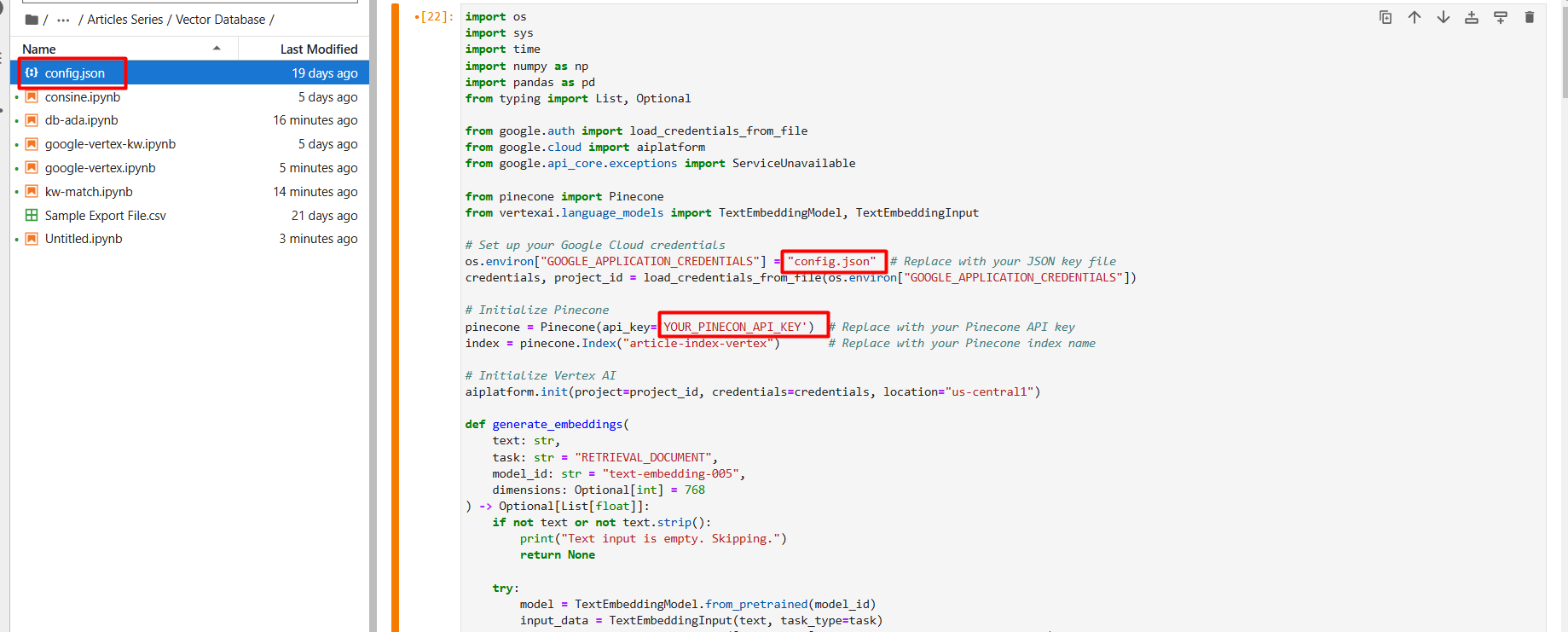
Benennen Sie die JSON-Datei in config.json um und laden Sie sie (über das Pfeil-nach-oben-Symbol) in Ihren Jupyter Notebook-Projektordner hoch.
 Screenshot von Google Cloud Console, Dezember 2024
Screenshot von Google Cloud Console, Dezember 2024Erstellen Sie im ersten Schritt der Konfiguration eine neue Vektordatenbank namens artikel-index-vertex, indem Sie die Dimension 768 manuell festlegen.
Sobald sie erstellt wurde, können Sie dieses Skript ausführen, um mit der Generierung von Vektor-Embeddings aus derselben Beispieldatei mithilfe von Google Vertex AI zu beginnen. text-embedding-005 (Sie können text-multilingual-embedding-002 wählen, wenn Ihr Text nicht auf Englisch ist).
import os
import sys
import time
import numpy as np
import pandas as pd
from typing import List, Optional
from google.auth import load_credentials_from_file
from google.cloud import aiplatform
from google.api_core.exceptions import ServiceUnavailable
from pinecone import Pinecone
from vertexai.language_models import TextEmbeddingModel, TextEmbeddingInput
# Richten Sie Ihre Google Cloud-Zugangsdaten ein.
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "config.json" # Ersetzen Sie mit Ihrer JSON-Key-Datei.
credentials, project_id = load_credentials_from_file(os.environ["GOOGLE_APPLICATION_CREDENTIALS"])
# Initialize Pinecone
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY') # Replace with your Pinecone API key.
index = pinecone.Index("article-index-vertex") # Replace with your Pinecone index name
# Initialize Vertex AI
aiplatform.init(project=project_id, credentials=credentials, location="us-central1")
def generate_embeddings(
text: str,
task: str = "RETRIEVAL_DOCUMENT",
model_id: str = "text-embedding-005",
dimensions: Optional[int] = 768
) -> Optional[List[float]]:
if not text or not text.strip():
print("Text input is empty. Skipping.")
return None
try:
model = TextEmbeddingModel.from_pretrained(model_id)
input_data = TextEmbeddingInput(text, task_type=task)
vectors = model.get_embeddings([input_data], output_dimensionality=dimensions)
return vectors[0].values
except ServiceUnavailable as e:
print(f "Vertex AI service is unavailable: {e}")
return None
except Exception as e:
print(f "Fehler beim Erzeugen von Einbettungen: {e}")
return None
# Daten aus CSV laden
data = pd.read_csv("Sample Export File.csv") # Ersetzen mit Ihrem CSV-Dateipfad
for idx, row in data.iterrows():
try:
permalink = str(row["Permalink"])
content = row["Inhalt"]
embedding = generate_embeddings(content)
if not embedding:
print(f "Skipping article ID {row['ID']} due to empty or failed embedding.")
weiter
print(f "Einbetten für {permalink}: {embedding[:5]}...")
sys.stdout.flush()
index.upsert(vectors=[
(
permalink,
embedding,
{
category': row['Category'],
title': row['Title'],
publish_date': row['Publish Date'],
type': row['Type'],
publish_year': row['Publish Year']]
}
)
])
time.sleep(1) # Optional: Sleep zur Vermeidung von Geschwindigkeitsbegrenzungen.
except Exception as e:
print(f "Fehler bei der Verarbeitung von Artikel ID {row['ID']}: {e}")
print("Alle Einbettungen werden in der Vektordatenbank gespeichert.")
Unten sehen Sie die Logs der erstellten Embeddings.
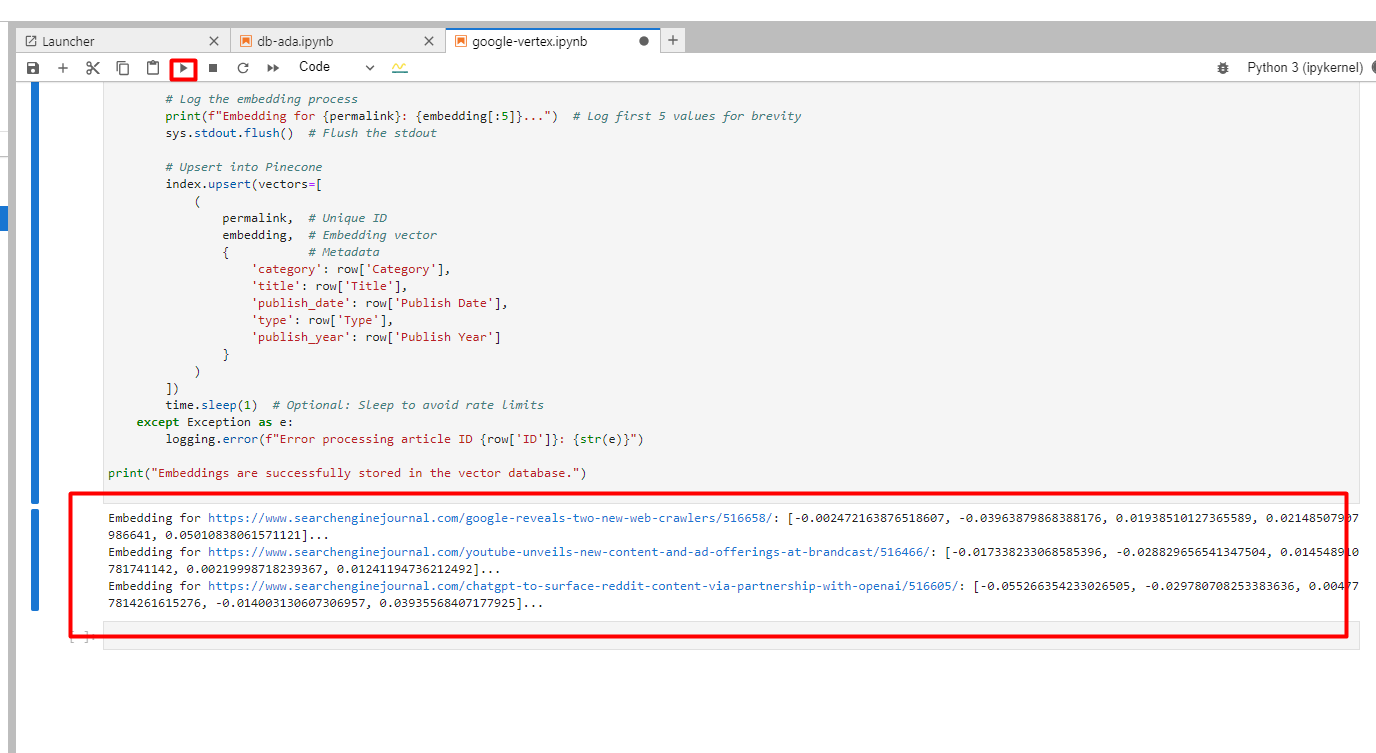 Screenshot von Google Cloud Console, Dezember 2024
Screenshot von Google Cloud Console, Dezember 20244. Suche nach einem Artikel, der einem Stichwort entspricht, mithilfe von Google Vertex AI
Lassen Sie uns nun dieselbe Suche nach Schlüsselwörtern mit Vertex AI durchführen. Es gibt eine kleine Nuance: Sie sollten "RETRIEVAL_QUERY" statt "RETRIEVAL_DOCUMENT" als Argument bei der Generierung von Keyword-Embeddings verwenden, da wir versuchen, einen Artikel (oder ein Dokument) zu suchen, der am besten zu unserer Phrase passt.
Arten von Aufgaben sind einer der Hauptvorteile von Vertex AI gegenüber den OpenAI-Modellen.
Es stellt sicher, dass die Embeddings die Intention der Schlüsselwörter erfassen, was für interne Links wichtig ist, und verbessert die Relevanz und Genauigkeit der in Ihrer Vektordatenbank gefundenen Übereinstimmungen.
Verwenden Sie dieses Skript, um Schlagwörter mit Vektoren abzugleichen.
import os
import pandas as pd
from google.cloud import aiplatform
from google.auth import load_credentials_from_file
from google.api_core.exceptions import ServiceUnavailable
from vertexai.language_models import TextEmbeddingModel
from pinecone import Pinecone
from tabulate import tabulate # Für Tabellenformatierungen
# Richten Sie Ihre Google Cloud-Zugangsdaten ein.
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "config.json" # Ersetzen Sie mit Ihrer JSON-Key-Datei.
credentials, project_id = load_credentials_from_file(os.environ["GOOGLE_APPLICATION_CREDENTIALS"])
# Initialize Pinecone client
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY') # Fügen Sie Ihren Pinecone API-Schlüssel hinzu.
index_name = "article-index-vertex" # Ersetzen Sie mit Ihrem Pinecone Indexnamen.
index = pinecone.Index(index_name)
# Vertex AI initialisieren
aiplatform.init(project=project_id, credentials=credentials, location="us-central1")
def generate_embeddings(
text: str,
model_id: str = "text-embedding-005".
) -> list:
"""
Generiert Einbettungen für den eingegebenen Text unter Verwendung des Einbettungsmodells von Google Vertex AI.
Gibt None zurück, wenn der Text leer ist oder ein Fehler auftritt.
"""
if not text or not text.strip():
print("Text-Eingabe ist leer. Skipping.")
return None
try:
model = TextEmbeddingModel.from_pretrained(model_id)
vector = model.get_embeddings([text]) # Removed 'task_type' and 'output_dimensionality'.
return vector[0].values
except ServiceUnavailable as e:
print(f "Vertex AI service is unavailable: {e}")
return None
except Exception as e:
print(f "Fehler beim Erzeugen von Einbettungen: {e}")
return None
def match_keywords_to_index(keywords):
"""
Matches eine Liste von keyword-category-Paaren zu den nächstgelegenen Artikeln im Pinecone-Index,
Filterung nach Metadaten, wenn angegeben.
"""
results = []
für keyword_pair in keywords:
keyword = keyword_pair[0].
category = keyword_pair[1].
try:
keyword_vector = generate_embeddings(keyword)
if not keyword_vector:
print(f "No embedding generated for keyword '{keyword}' in category '{category}'.").
results.append({
'Keyword': keyword,
'Category': Kategorie,
Match Score': 'Error/Empty',
Titel': 'No match',
URL': 'N/A'
})
weiter
query_results = index.query(
vector=keyword_vector,
top_k=1,
include_metadata=True,
filter={"category": category}
)
if query_results['matches']:
closest_match = query_results['matches'][0].
results.append({
'Keyword': keyword,
'Category': category,
Match Score': f"{closest_match['score']:.2f}",
Titel': closest_match['metadata'].get('title', 'N/A'),
URL': closest_match['id']]
})
else:
results.append({
'Keyword': keyword,
'Category': Kategorie,
Match Score': 'N/A',
Titel': 'No match found',
URL': 'N/A'
})
except Exception as e:
print(f "Fehler bei der Verarbeitung des Schlüsselworts '{keyword}' mit der Kategorie '{category}': {e}")
results.append({
'Keyword': keyword,
'Category': Kategorie,
Match Score': 'Error',
Title': 'Error occurred',
URL': 'N/A'
})
return results
# Beispiel Verwendung:
keywords = [["SEO Tools", "Tools"], ["TikTok", "TikTok"], ["SEO Consultant", "SEO"]]
matches = match_keywords_to_index(keywords)
# Die Ergebnisse in einer Tabelle anzeigen.
print(tabulate(matches, headers="keys", tablefmt="fancy_grid"))
Und Sie sehen die erzeugten Punktzahlen :
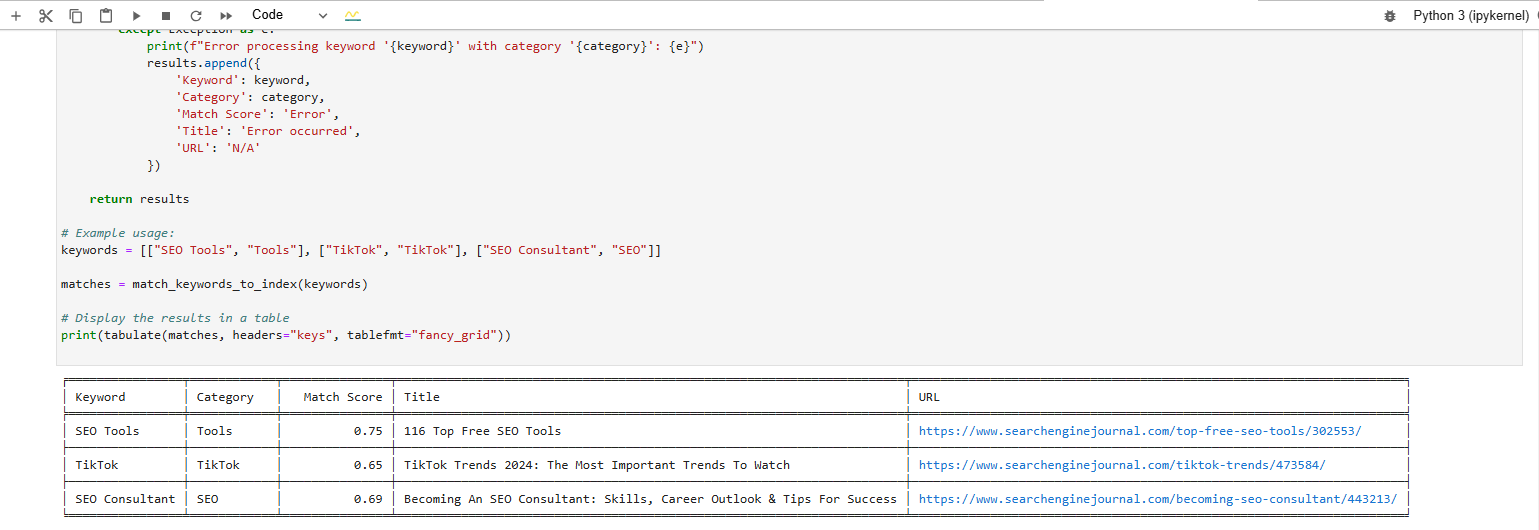 Keyword-Matching-Scores, die vom Textintegrationsmodell von Vertex AI erzeugt werden
Keyword-Matching-Scores, die vom Textintegrationsmodell von Vertex AI erzeugt werdenTesten Sie die Relevanz Ihrer Artikel
Dies ist ein vereinfachtes (breites) Mittel, um die semantische Ähnlichkeit Ihres Textes mit dem Hauptkeyword zu überprüfen. Erstellen Sie eine vektorbasierte Integration Ihres Top-Schlüsselwort und den gesamten Inhalt des Artikels über Googles Vertex-KI und berechnen eine Kosinus-Ähnlichkeit.
Wenn Ihr Text zu lang ist, sollten Sie vielleicht in Erwägung ziehen, die Funktion Ausschnittstrategien.
Eine Punktzahl, die nahe bei 1,0 liegt (wie 0,8 oder 0,7). bedeutet, dass Sie nahe genug sind zu diesem Thema. Wenn Ihre Punktzahl niedriger ist, kann es sein, dass eine zu lange Einleitung mit vielen oberflächlichen Elementen zu einer Verwässerung der Relevanz führt und das Weglassen der Einleitung dazu beiträgt, die Relevanz zu erhöhen.
Denken Sie aber daran, dass jede vorgenommene Änderung aus redaktioneller Sicht und im Hinblick auf die Nutzererfahrung sinnvoll sein muss.
Sie können sogar einen schnellen Vergleich durchführen, indem Sie den gut bewerteten Inhalt eines Konkurrenten einbinden und sich mit ihm vergleichen.
Dadurch können Sie Ihre Inhalte genauer auf das Zielthema ausrichten, was Ihnen zu einem besseren Ranking verhelfen kann.
Es gibt bereits Werkzeuge, die führen solche Aufgaben ausaber der Erwerb dieser Fähigkeiten wird Sie in die Lage versetzen, einen persönlichen Ansatz zu verfolgen, der auf Ihre Bedürfnisse zugeschnitten ist, und das natürlich kostenlos.
Selbst zu experimentieren und sich diese Fähigkeiten anzueignen, wird Ihnen helfen, in Sachen KI-SEO immer einen Schritt voraus zu sein und fundierte Entscheidungen zu treffen.
Als zusätzliche Lektüre empfehle ich Ihnen diese hervorragenden Artikel :
Weitere Ressourcen :
Vorgehobenes Bild : Aozorastock/Shutterstock