Una base de datos vectorial es una colección de datos en la que cada dato se almacena en forma de vector (digital). Un vector representa un objeto o entidad, como una imagen, una persona, un lugar, etc. en un espacio abstracto de N dimensiones.
Vectores, como se explica en el capítulo anteriorson esenciales para identificar cómo se relacionan las entidades y pueden utilizarse para encontrar su similitud semántica. Esto puede aplicarse de varias formas con fines de SEO, como agrupar palabras clave o contenidos similares (utilizando kNN).
En este artículo, veremos algunas formas de aplicar la IA al SEO, incluida la búsqueda de contenidos semánticamente similares para los enlaces internos. Esto puede ayudarte a perfeccionar tu estrategia de contenidos en un momento en el que los motores de búsqueda son cada vez más motores de búsqueda. confían cada vez más en los LLM.
También puede leer un artículo anterior de esta serie sobre cómo encontrar canibalización de palabras clave mediante la integración de textos de OpenAI.
Vamos a sumergirnos aquí para empezar a construir la base de nuestra herramienta.
Comprender las bases de datos vectoriales
Si tiene miles de artículos y quiere encontrar la similitud semántica más cercana para su consulta objetivo, no puede crear incrustaciones vectoriales para todos los artículos sobre la marcha para compararlos, ya que esto es muy ineficiente.
Para que esto fuera posible, los vectores de incrustación tendrían que generarse una vez y almacenarse en una base de datos que pudiera consultarse para encontrar el artículo más cercano.
Esto es lo que hacen las bases de datos vectoriales: son tipos especiales de bases de datos que almacenan insets (vectores).
Cuando se consulta la base de datos, a diferencia de las bases de datos tradicionales, éstas realizan las siguientes operaciones correspondencia por similitud coseno y devuelve los vectores (en este caso, artículos) más cercanos a otro vector (en este caso, una palabra clave) consultado.
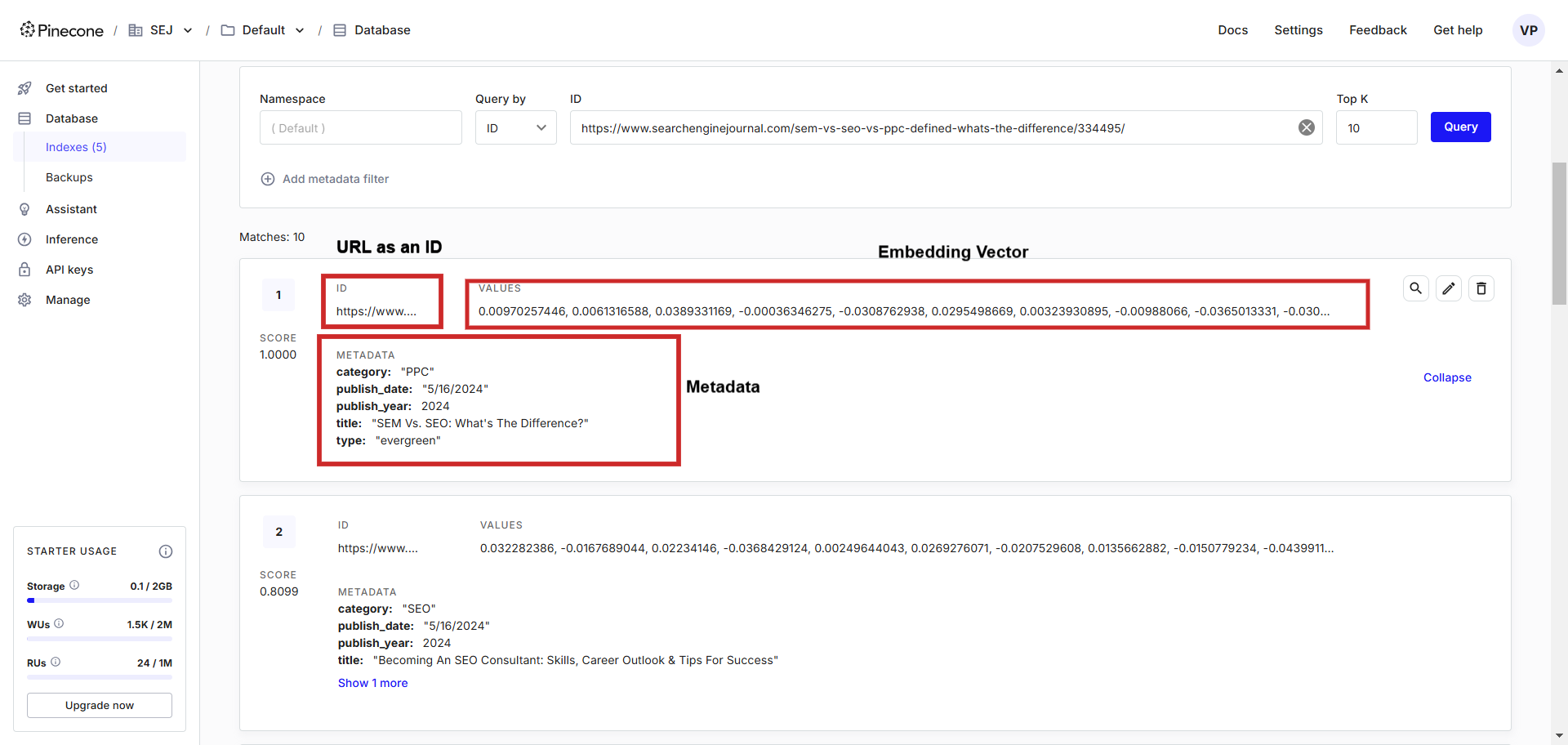
Este es su aspecto:
En la base de datos de vectores, se pueden ver los vectores con los metadatos almacenados, que podemos fácil de interrogar utilizando el lenguaje de programación de nuestra elección.
En este artículo utilizaremos Piña por su facilidad de comprensión y sencillez de uso, pero hay otros proveedores como Croma, BigQueryo Qdrant que puede consultar.
Vayamos al meollo de la cuestión.
1. Crear una base de datos vectorial
En primer lugar, crea una cuenta en Pinecone y crea un índice con la configuración "text-embedding-ada-002" con "coseno" como métrica para medir la distancia vectorial. Puedes darle al índice el nombre que quieras, pero nosotros lo llamaremosarticle-index-all-ada'.
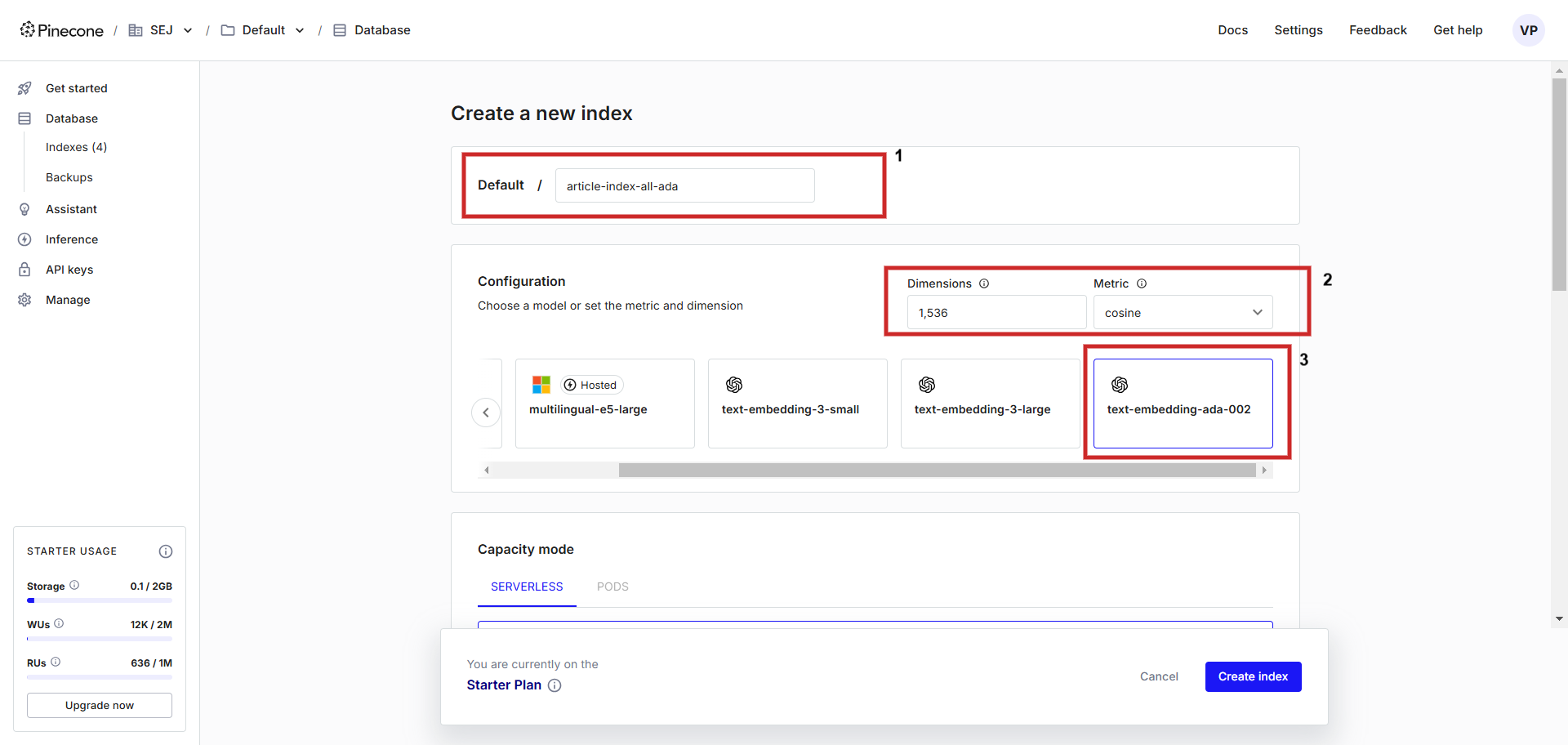 Creación de una base de datos vectorial.
Creación de una base de datos vectorial.Esta interfaz de ayuda sólo está ahí para ayudarle durante la configuración. Si desea almacenar la integración vectorial Vertex AI, debe establecer 'dimensions' en 768 en la pantalla de configuración para que coincida con la dimensionalidad por defecto y puede almacenar vectores de texto Vertex AI (puede definir un valor de dimensión de 1 à 768 para ahorrar memoria).
En este artículo, aprenderemos a utilizar las funciones 'text-embedding-ada-002' y 'text-embedding-ada-002' de OpenAi. Vertex AI de Google plantillas "text-embedding-005".
Una vez creada, necesitamos una clave API para poder conectarnos a la base de datos utilizando la URL del host de la base de datos del vector.
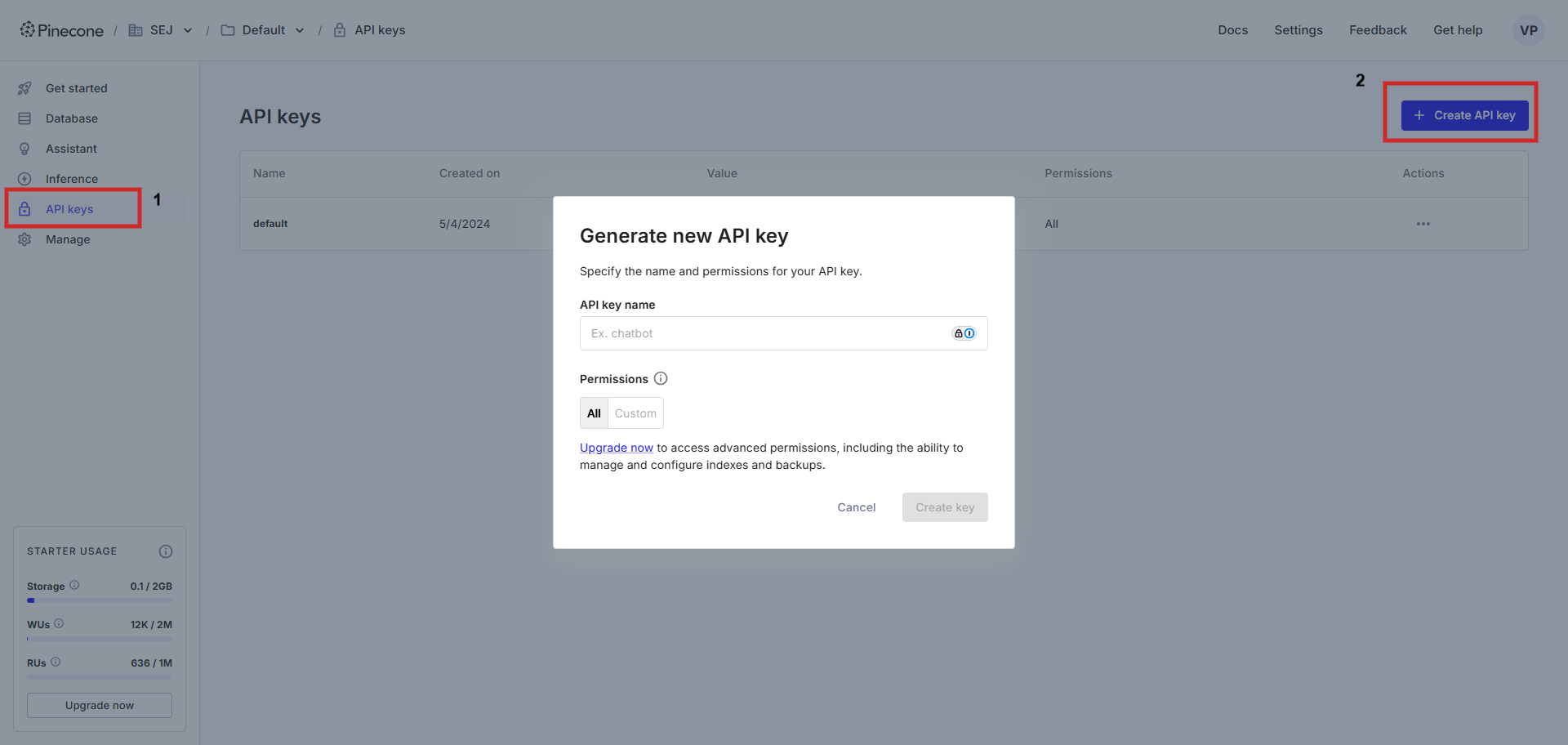
Generar una clave API
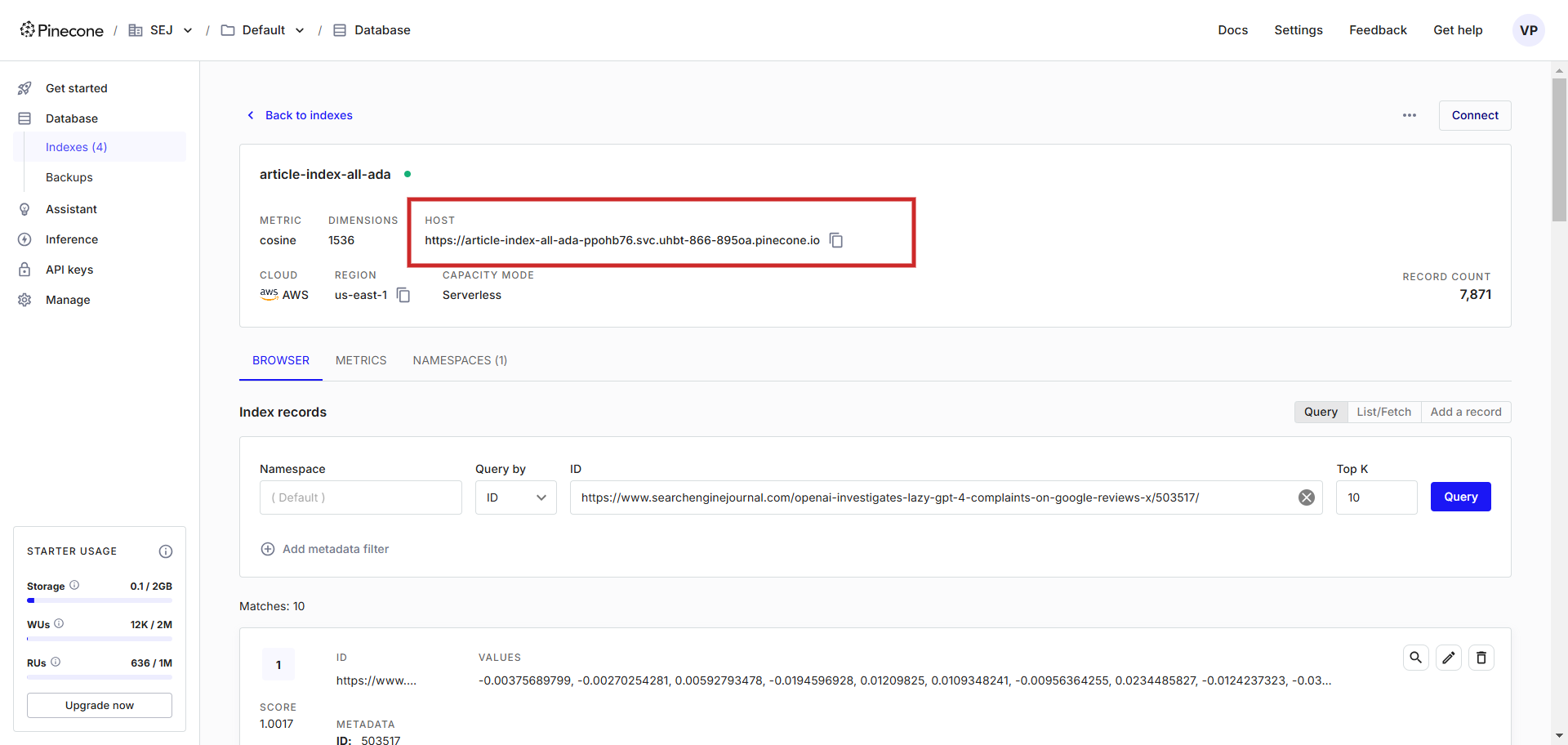
URL del host de la base de datos vectorial
A continuación, debe utilizar Cuaderno Jupyter. Si no lo tiene instalado, siga estas instrucciones esta guía para instalarlo y, a continuación, ejecute este comando (más abajo) en el terminal de su PC para instalar todos los paquetes necesarios.
pip install openai google-cloud-aiplatform google-auth pandas pinecone-client tabulate ipython numpyY no olvides que ChatGPT es muy útil cuando tienes problemas durante la codificación.
2. Exporte sus artículos desde su CMS
A continuación, tenemos que preparar un archivo de exportación CSV de los artículos en su CMS. Si usas WordPress, puedes usar un plugin para hacerlo. exportaciones a medida.
Dado que nuestro objetivo final es construir una herramienta de enlace interno, tenemos que decidir qué datos deben transferirse a la base de datos vectorial como metadatos. En esencia, el filtrado basado en metadatos actúa como una capa adicional de orientación de la búsqueda, alineándola con la orientación general de la base de datos vectorial. Marco RAG integrando conocimientos externos, lo que contribuirá a mejorar la calidad de la investigación.
Por ejemplo, si publicamos un artículo sobre "PPC" y queremos insertar un enlace a la expresión "Investigación de palabras clave", podemos especificar en nuestra herramienta que "Categoría=PPC". Esto permitirá a la herramienta consultar sólo artículos de la categoría "PPC", garantizando un enlace preciso y contextualmente relevante, o puede que queramos enlazar con la frase "La actualización más reciente de Google" y limitar la coincidencia a sólo artículos de noticias que utilicen "Tipo" y se hayan publicado este año.
En nuestro caso, exportaremos :
- Título.
Categoría. - Tipo.
- Fecha de publicación.
- Año de publicación.
- Permalink.
- Meta Descripción.
- Contenido.
Para obtener los mejores resultados, concatenaremos los campos título y meta-descripción, ya que son la mejor representación del artículo que podemos vectorizar y son ideales para la integración y la creación de enlaces internos.
Utilizar todo el contenido del artículo para la integración puede reducir la precisión y diluir la relevancia de los vectores.
Esto se debe a que una sola incrustación de gran tamaño intenta representar varios temas tratados en el artículo al mismo tiempo, lo que da lugar a una representación menos centrada y pertinente. Agrupación estrategias (dividir el artículo en títulos naturales o segmentos semánticamente significativos), pero no es el tema de este artículo.
Este es el artículo ejemplo de fichero de exportación que puede descargar y utilizar para nuestro código de ejemplo a continuación.
2. Inserción de codificaciones de texto OpenAi en la base de datos vectorial
Suponiendo que ya disponga de una base de datos Clave API de OpenAIEste código genera incrustaciones vectoriales a partir del texto y las inserta en la base de datos vectorial de Pinecone.
importar pandas como pd
from openai import OpenAI
from pinecone import Pinecone
from IPython.display import clear_output
# Configura tus claves API de OpenAI y Pinecone
openai_client = OpenAI(api_key='YOUR_OPENAI_API_KEY') # Instanciar el cliente OpenAI
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY')
# Conectar a un índice Pinecone existente
index_name = "articulo-index-todo-ada"
index = pinecone.Index(nombre_índice)
def generar_incrustaciones(texto):
"""
Genera una incrustación para el texto dado utilizando la API de OpenAI.
Devuelve None si el texto no es válido o se produce un error.
"""
intentar:
if not text or not isinstance(text, str):
raise ValueError("El texto de entrada debe ser una cadena no vacía.")
result = openai_client.embeddings.create(
input=texto,
model="text-embedding-ada-002"
)
clear_output(wait=True) # Borrar salida para una nueva visualización
if hasattr(result, 'data') and len(result.data) > 0:
print("Respuesta API:", resultado)
return resultado.datos[0].incrustación
else:
raise ValueError("Respuesta no válida de la API OpenAI. No se han devuelto datos.")
except ValueError as ve:
print(f "ValueError: {ve}")
return None
excepto Exception como e:
print(f "Se ha producido un error al generar incrustaciones: {e}")
return None
# Carga tus artículos desde un CSV
df = pd.read_csv('Ejemplo de archivo de exportación.csv')
# Procesa cada artículo
para idx, fila en df.iterrows():
try:
clear_output(wait=True)
contenido = fila["Contenido"]
vector = generate_embeddings(contenido)
si vector es None
print(f "Skipping article ID {row['ID']} due to empty or invalid embedding.")
continuar
index.upsert(vectores=[
(
fila['Permalink'], # ID único
vector, # La incrustación
{
title': fila['Título'],
'category': fila['Categoría'],
'type': fila['Tipo'],
'publish_date': fila['Fecha de publicación'],
publish_year': fila['Año de publicación']
}
)
])
except Exception as e:
clear_output(wait=True)
print(f "Error al procesar el ID del artículo {fila['ID']}: {str(e)}")
print("Las incrustaciones se han almacenado correctamente en la base de datos de vectores.")
Debe crear un archivo de bloc de notas y copiarlo y pegarlo; a continuación, cargue el archivo CSV 'Sample Export File.csv' en la misma carpeta.
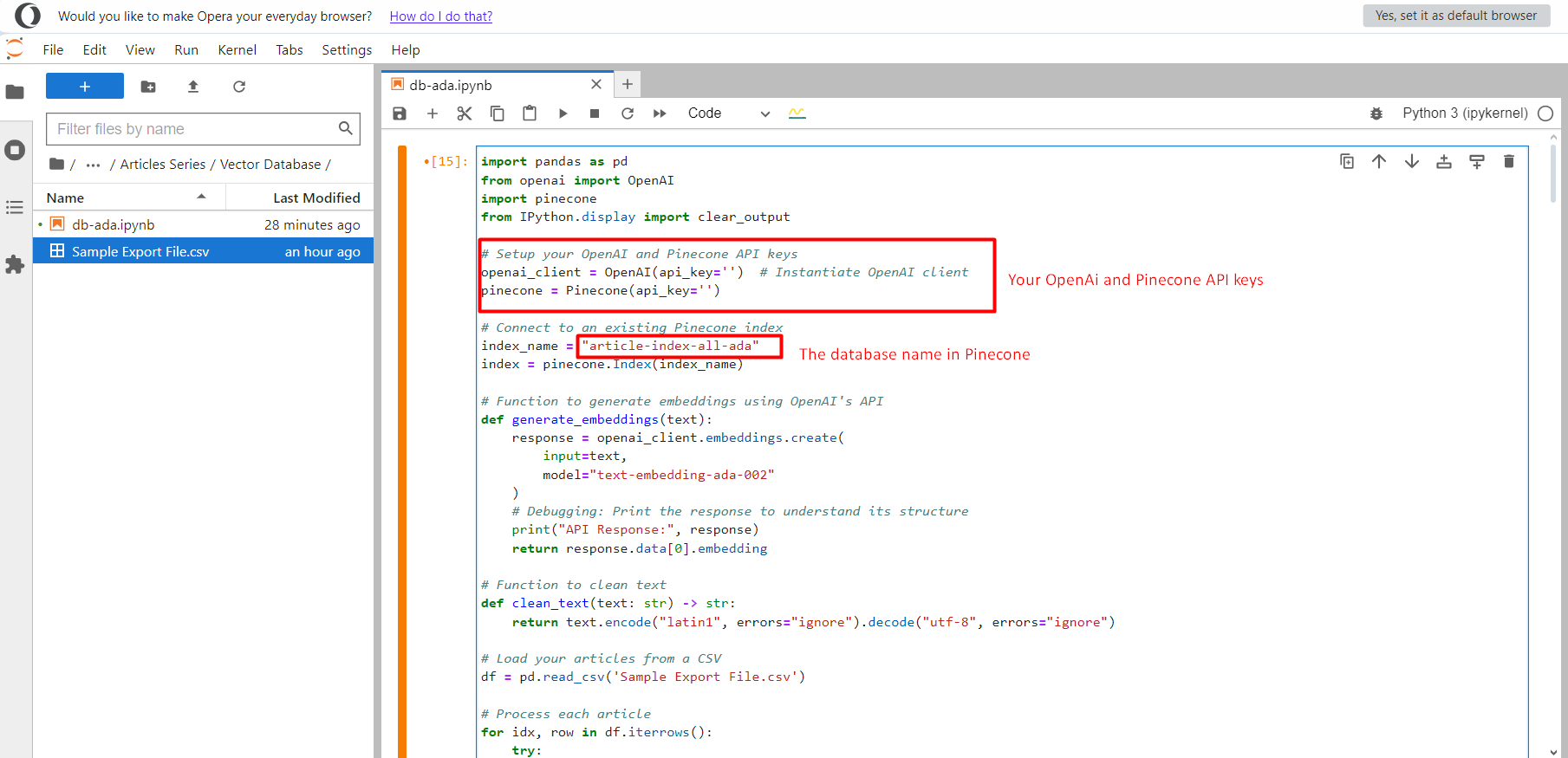 Proyecto Jupyter.
Proyecto Jupyter.Una vez hecho esto, haga clic en el botón Ejecutar y comenzará a empujar todos los vectores de integración de texto en el índice. article-index-all-ada que creamos en la primera etapa.
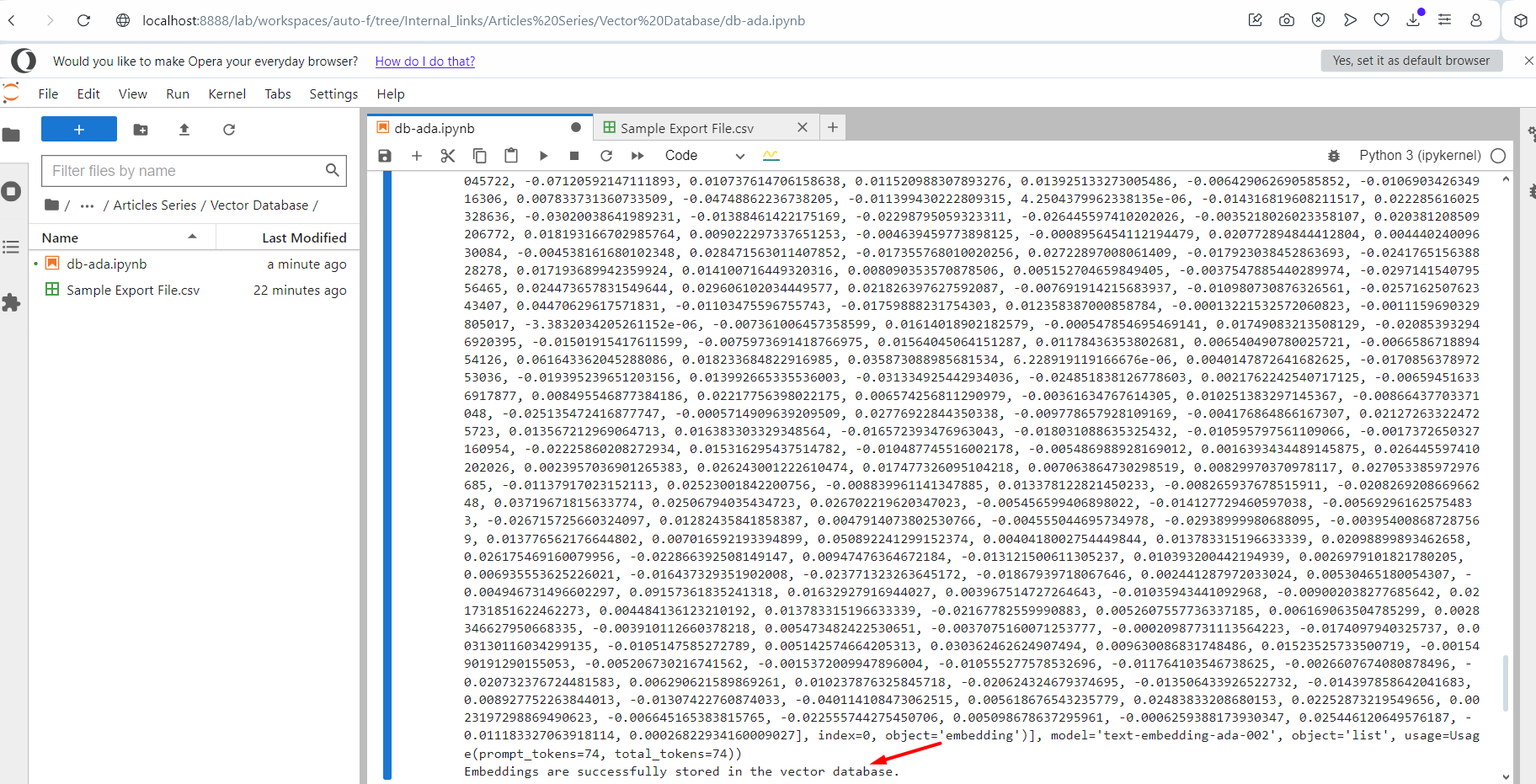 Ejecutando el script.
Ejecutando el script.Verá el texto del registro de salida del vector de integración. Una vez finalizado el script, mostrará un mensaje al final indicando que se ha ejecutado correctamente. Ahora comprueba tu índice en el Pinecone y verás tu se puede encontrar allí.
3. Buscar un artículo correspondiente a una palabra clave
Ahora vamos a intentar encontrar un artículo que coincida con la palabra clave.
Crea un nuevo archivo de bloc de notas y copia y pega este código.
from openai import OpenAI
from pinecone import Pinecone
from IPython.display import clear_output
from tabulate import tabulate # Importar tabulate para formatear tablas
# Configura tus claves API de OpenAI y Pinecone
openai_client = OpenAI(api_key='YOUR_OPENAI_API_KEY') # Instanciar el cliente OpenAI
pinecone = Pinecone(api_key='YOUR_OPENAI_API_KEY')
# Conectar a un índice Pinecone existente
index_name = "articulo-index-todo-ada"
index = pinecone.Index(nombre_índice)
# Función para generar incrustaciones utilizando la API de OpenAI
def generar_incrustaciones(texto):
"""
Genera una incrustación para un texto dado utilizando la API de OpenAI.
"""
prueba:
if not text or not isinstance(text, str):
raise ValueError("El texto de entrada debe ser una cadena no vacía.")
result = openai_client.embeddings.create(
input=texto,
model="text-embedding-ada-002"
)
# Debugging: Imprime la respuesta para entender su estructura
clear_output(wait=True)
#print("Respuesta API:", resultado)
if hasattr(result, 'data') and len(result.data) > 0:
return resultado.datos[0].incrustación
else:
raise ValueError("Respuesta no válida de la API OpenAI. No se han devuelto datos.")
except ValueError as ve:
print(f "ValueError: {ve}")
return Ninguno
excepto Exception como e:
print(f "Se ha producido un error al generar incrustaciones: {e}")
return None
# Función para consultar el índice Pinecone con palabras clave y metadatos
def match_keywords_to_index(keywords):
"""
Compara una lista de palabras clave con el artículo más cercano en el índice Pinecone, filtrando por metadatos dinámicamente.
"""
resultados = []
para par_palabra_clave en palabras_clave:
try:
clear_output(wait=True)
# Extrae la palabra clave y la categoría de la submatriz
palabra clave = par_palabras_clave[0]
categoría = par_palabras_clave[1]
# Genera la incrustación de la palabra clave actual
vector = generar_incrustaciones(palabra_clave)
si vector es None
print(f "Se omite la palabra clave '{palabra clave}' debido a un error de incrustación.")
continuar
# Consulta el índice Pinecone en busca del vector más cercano con filtro de metadatos
query_results = index.query(
vector=vector, # La incrustación de la palabra clave
top_k=1, # Recuperar sólo la coincidencia más cercana
include_metadata=True, # Incluir metadatos en los resultados
filter={"category": categoría} # Filtrar los resultados por categoría de metadatos de forma dinámica
)
# Almacenar la coincidencia más cercana
if consulta_resultados['coincidencias']:
coincidencia_más_cercana = query_results['coincidencias'][0]
results.append({
'Palabra clave': palabra clave, # La palabra clave buscada
Categoría": category, # Categoría utilizada para el filtrado
'Match Score': f"{closest_match['score']:.2f}", # Puntuación de similitud (con 2 decimales)
'Title': closest_match['metadata'].get('title', 'N/A'), # Título del artículo
'URL': closest_match['id'] # Usando 'id' como URL
})
else:
results.append({
'Palabra clave': palabra clave,
Categoría: category,
'Match Score': 'N/A',
'Título': 'No se ha encontrado ninguna coincidencia',
'URL': 'N/A
})
except Exception as e:
clear_output(wait=True)
print(f "Error al procesar la palabra clave '{palabra clave}' con la categoría '{categoría}': {e}")
results.append({
Palabra clave': palabra clave,
Categoría: categoría,
Puntuación': 'Error',
'Título': 'Se ha producido un error',
'URL': 'N/A
})
devolver resultados
# Ejemplo de uso: Buscar coincidencias para una matriz de palabras clave y categorías
keywords = [["Herramientas SEO", "SEO"], ["TikTok", "TikTok"], ["Consultor SEO", "SEO"]] # Reemplace con sus palabras clave y categorías
matches = match_keywords_to_index(palabras clave)
# Muestra los resultados en una tabla
print(tabulate(matches, headers="keys", tablefmt="fancy_grid"))
Estamos tratando de encontrar una coincidencia para estas palabras clave:
- Herramientas SEO.
- TikTok.
- Consultor SEO.
Y aquí está el resultado que obtenemos después de ejecutar el código:
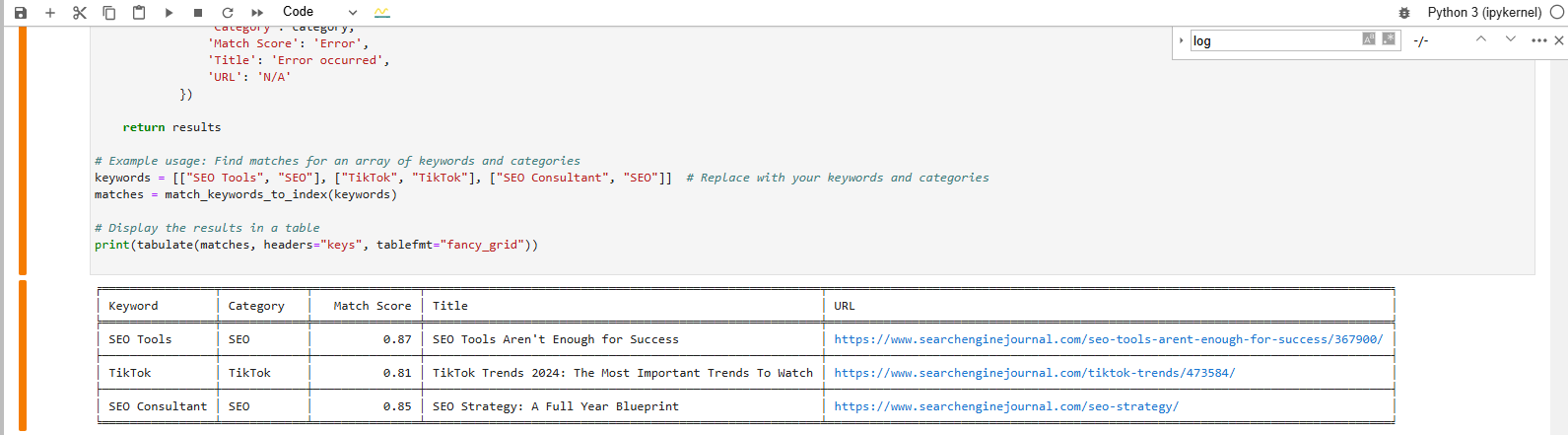 Buscar una coincidencia para la expresión de la palabra clave en la base de datos de vectores
Buscar una coincidencia para la expresión de la palabra clave en la base de datos de vectoresLa tabla formateada de la parte inferior de la página muestra los artículos más próximos a nuestras palabras clave.
4. Inserción de integraciones de texto de Google Vertex AI en la base de datos de vectores
Ahora hagamos lo mismo, pero con Google Vertex AI 'incrustación de texto-005incrustación". Este modelo destaca por haber sido desarrollado por Google, las autoridades públicas y el sector privado. Vértice AI búsqueday está específicamente entrenado para realizar tareas de búsqueda y correspondencia de consultas, por lo que se adapta bien a nuestro caso de uso.
Incluso puedes construir un widget de búsqueda interna y añádalo a su sitio web.
Comience por conectarse a Google Cloud Console y a crear un proyecto. Entonces, desde el Biblioteca API encuentra la API Vertex AI y actívala.
 Captura de pantalla de Google Cloud Console, diciembre de 2024
Captura de pantalla de Google Cloud Console, diciembre de 2024Configure su cuenta de facturación para poder utilizar Vertex AI según los precios. $0.0002 por 1.000 caracteres (y ofrece 300 créditos $ a los nuevos usuarios).
Una vez definido, debe ir a la siguiente dirección Servicios API > ; Credenciales crear una cuenta de servicio, generar una clave y descargarla en formato JSON.
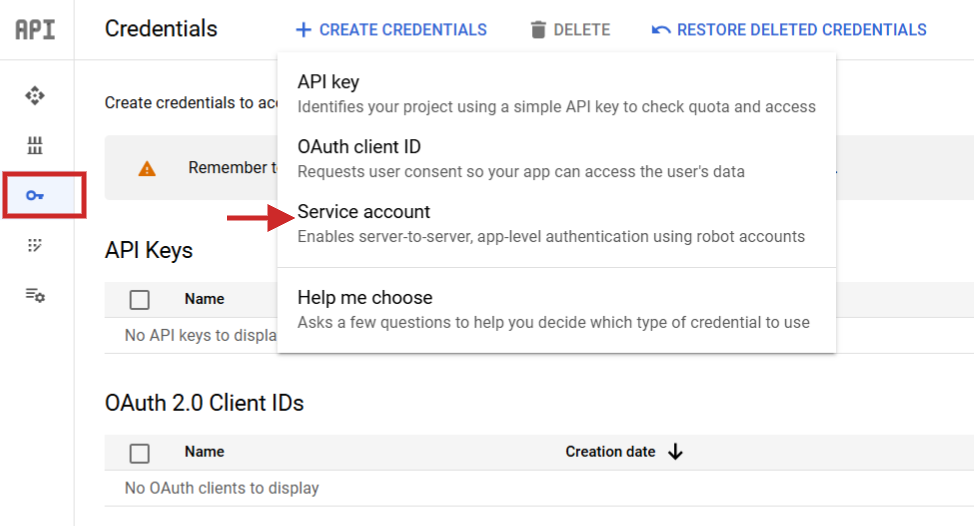
Paso 1: Crear una cuenta de Service a
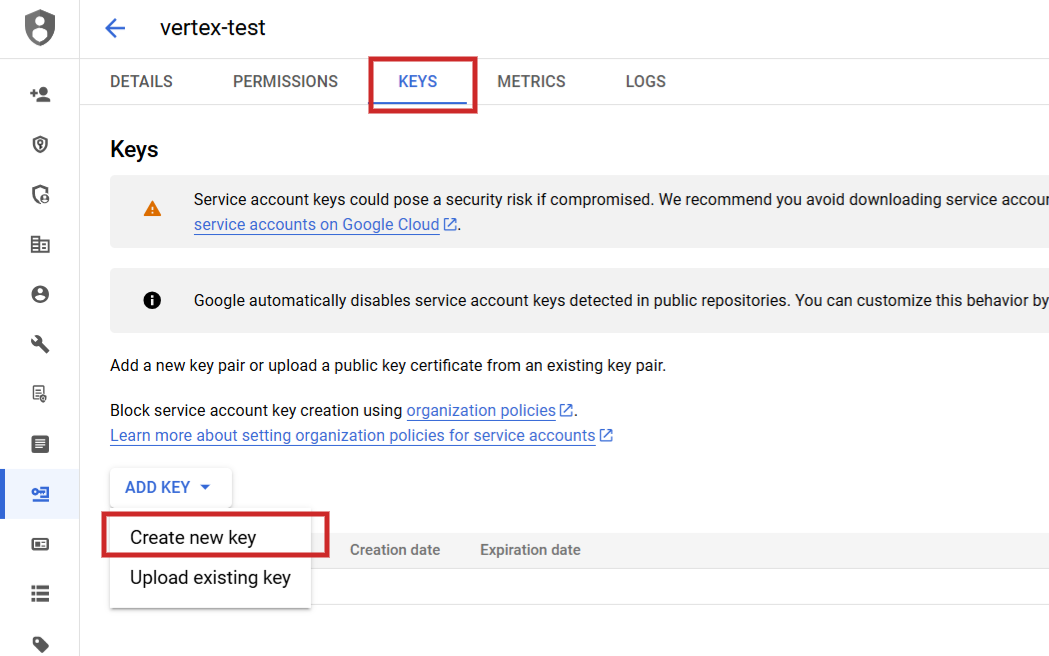
Paso 2: Añadir una nueva clave en la pestaña Claves de cuenta de servicio
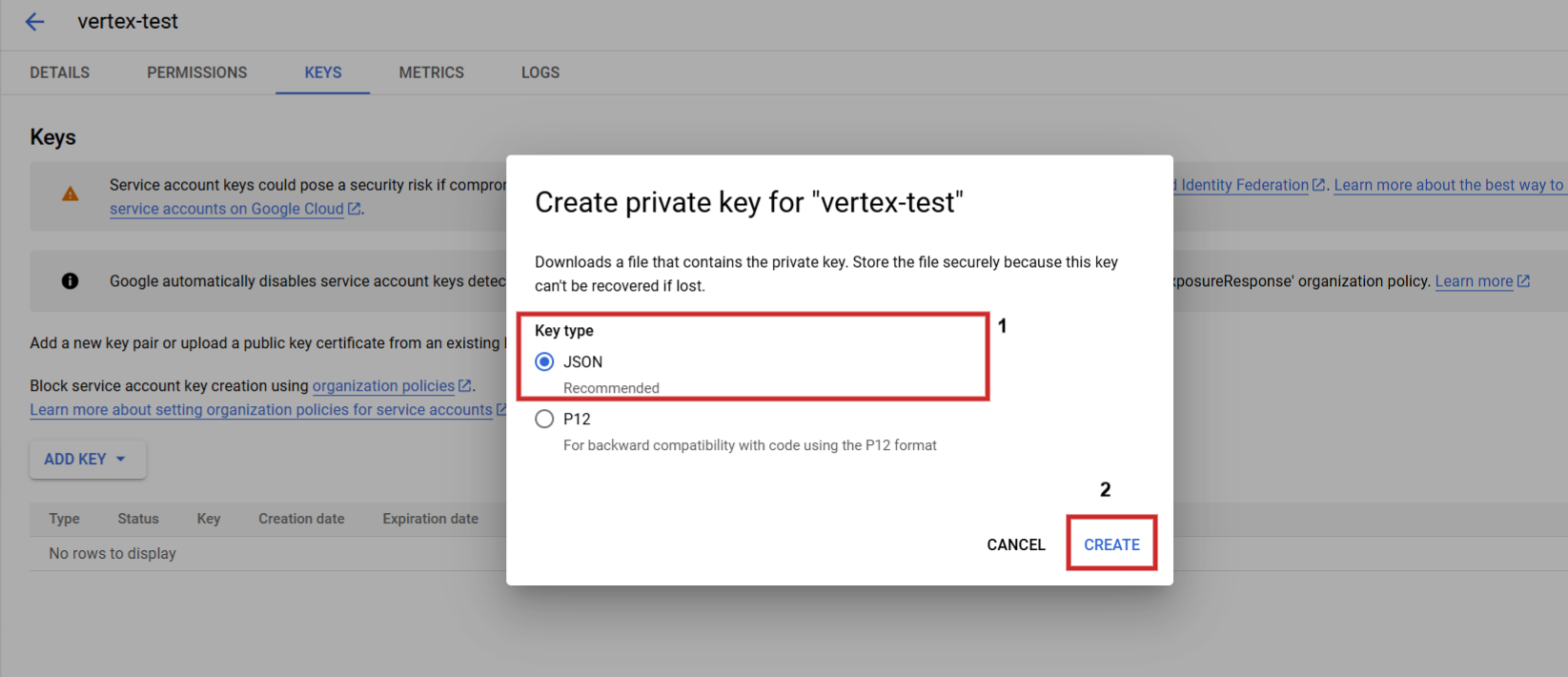
Paso 3: Crear una clave JSON
Cambia el nombre del archivo JSON a config.json y súbelo (mediante el icono de la flecha hacia arriba) a la carpeta de tu proyecto Jupyter Notebook.
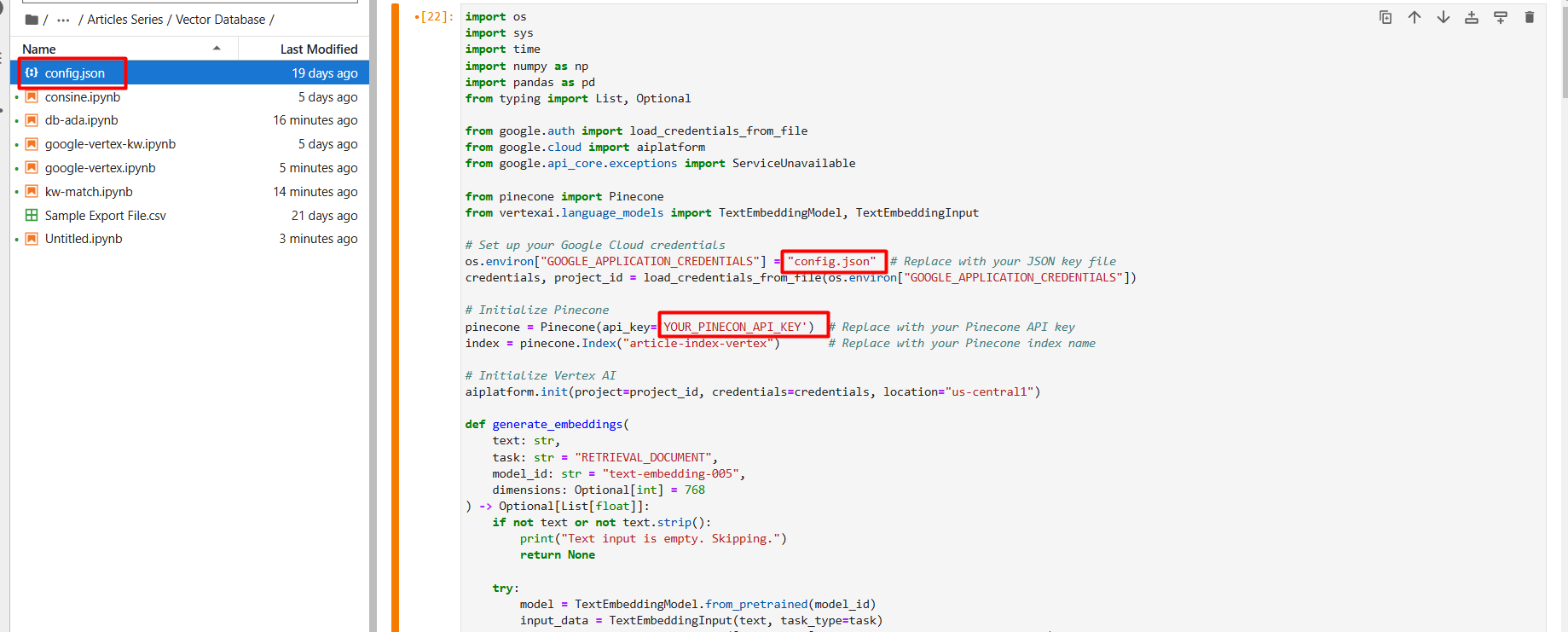 Captura de pantalla de Google Cloud Console, diciembre de 2024
Captura de pantalla de Google Cloud Console, diciembre de 2024En la primera etapa de configuración, cree una nueva base de datos vectorial llamada artículo-índice-vértice definiendo manualmente la dimensión 768.
Una vez creado, puede ejecutar este script para empezar a generar incrustaciones vectoriales a partir del mismo archivo de ejemplo utilizando Google Vertex AI. incrustación de texto-005 (puede elegir text-multilingual-embedding-002 si su texto no está en inglés).
importar os
importar sys
import tiempo
import numpy como np
import pandas como pd
from typing import Lista, Opcional
from google.auth import carga_credenciales_desde_archivo
from google.cloud import aiplatform
from google.api_core.exceptions import ServiceUnavailable
from pinecone import Pinecone
from vertexai.language_models import TextEmbeddingModel, TextEmbeddingInput
# Configura tus credenciales de Google Cloud
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "config.json" # Sustitúyelo por tu archivo de claves JSON
credentials, project_id = load_credentials_from_file(os.environ["GOOGLE_APPLICATION_CREDENTIALS"])
# Inicializar Pinecone
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY') # Reemplazar con su clave API Pinecone
index = pinecone.Index("article-index-vertex") # Sustituir por el nombre de su índice Pinecone
# Inicializar Vertex AI
aiplatform.init(project=project_id, credentials=credenciales, location="us-central1")
def generar_embeddings(
texto: str,
tarea: str = "RETRIEVAL_DOCUMENT",
model_id: str = "text-embedding-005",
dimensiones: Optional[int] = 768
) -> Opcional[Lista[float]]:
if not text or not text.strip():
print("La entrada de texto está vacía. Se omite.")
return None
probar:
model = TextEmbeddingModel.from_pretrained(model_id)
input_data = TextEmbeddingInput(text, task_type=tarea)
vectores = model.get_embeddings([datos_entrada], dimensionalidad_salida=dimensiones)
return vectores[0].valores
except ServiceUnavailable as e:
print(f "El servicio de IA de vértices no está disponible: {e}")
return Ninguno
except Exception as e:
print(f "Error al generar incrustaciones: {e}")
return None
# Cargar datos desde CSV
data = pd.read_csv("Archivo de exportación de ejemplo.csv") # Sustituir por la ruta del archivo CSV
for idx, row in data.iterrows():
try:
permalink = str(fila["Permalink"])
contenido = fila["Contenido"]
incrustación = generate_embeddings(contenido)
if not embedding:
print(f "Skipping article ID {row['ID']} due to empty or failed embedding.")
continuar
print(f "Incrustación para {permalink}: {incrustación[:5]}...")
sys.stdout.flush()
index.upsert(vectores=[
(
permalink,
incrustación,
{
categoría: fila['Categoría'],
'title': fila['Título'],
'publish_date': fila['Fecha de publicación'],
'type': fila['Tipo'],
publish_year': fila['Año de publicación']
}
)
])
time.sleep(1) # Opcional: Sleep para evitar límites de velocidad
except Exception as e:
print(f "Error al procesar el ID del artículo {fila['ID']}: {e}")
print("Todas las incrustaciones están almacenadas en la base de datos de vectores.")
A continuación puedes ver los registros de las incrustaciones creadas.
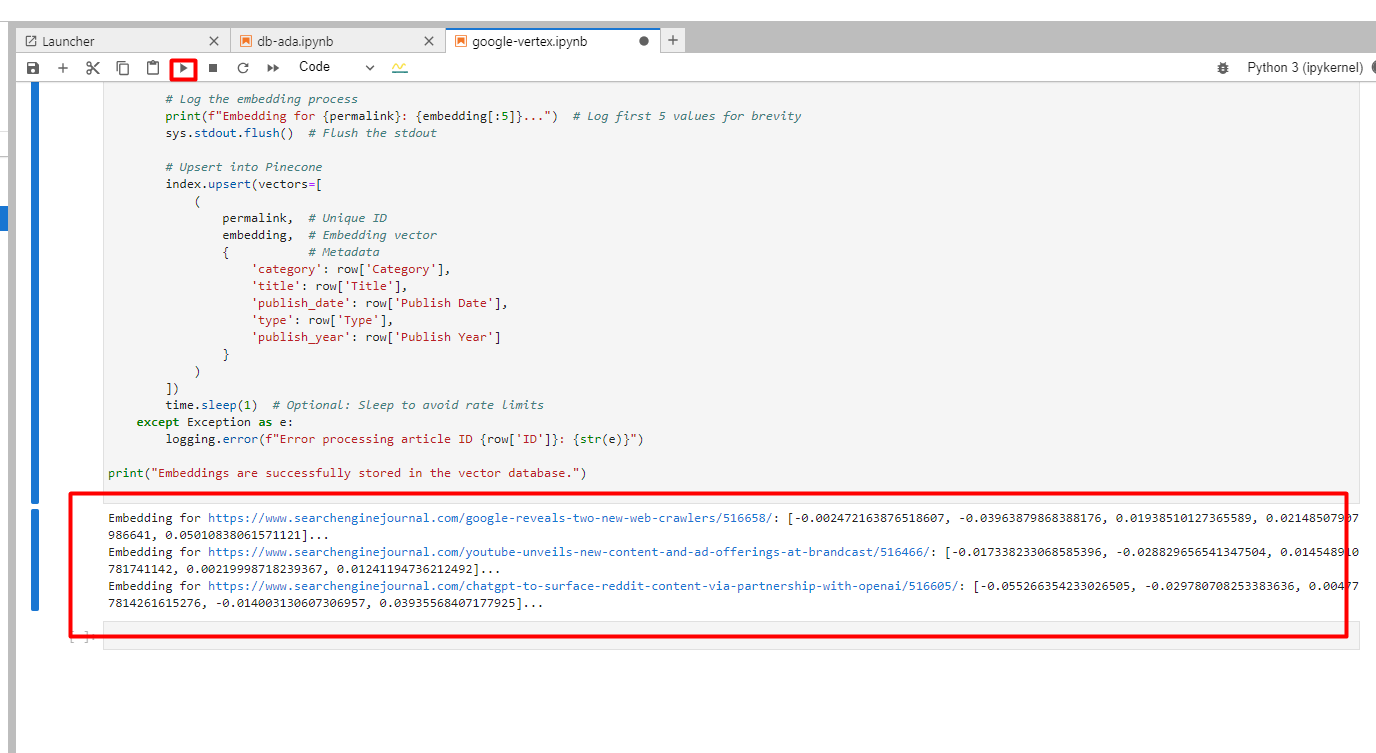 Captura de pantalla de Google Cloud Console, diciembre de 2024
Captura de pantalla de Google Cloud Console, diciembre de 20244. Búsqueda de un artículo que coincida con una palabra clave utilizando Google Vertex AI
Hagamos ahora la misma búsqueda de palabras clave con Vertex AI. Hay un pequeño matiz: es necesario utilizar 'RETRIEVAL_QUERY' en lugar de 'RETRIEVAL_DOCUMENT' como argumento al generar incrustaciones de palabras clave, porque estamos tratando de encontrar un artículo (o documento) que mejor coincida con nuestra frase.
Tipos de tareas son una de las principales ventajas de Vertex AI sobre los modelos OpenAI.
Garantiza que las incrustaciones capten la intención de las palabras clave, lo que es importante para los enlaces internos, y mejora la relevancia y precisión de las coincidencias encontradas en su base de datos vectorial.
Utilice este script para relacionar palabras clave con vectores.
importar os
importar pandas como pd
from google.cloud import aiplatform
from google.auth import carga_credenciales_desde_archivo
from google.api_core.exceptions import ServiceUnavailable
from vertexai.language_models import TextEmbeddingModel
from pinecone import Pinecone
from tabulate import tabulate # Para el formato de tablas
# Configura tus credenciales de Google Cloud
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "config.json" # Sustitúyelo por tu archivo de claves JSON
credentials, project_id = load_credentials_from_file(os.environ["GOOGLE_APPLICATION_CREDENTIALS"])
# Inicializar cliente Pinecone
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY') # Añade tu clave API Pinecone
index_name = "article-index-vertex" # Sustitúyalo por el nombre de su índice Pinecone
index = pinecone.Index(nombre_índice)
# Inicializar Vertex AI
aiplatform.init(project=project_id, credentials=credenciales, location="us-central1")
def generar_embeddings(
texto: str,
model_id: str = "text-embedding-005"
) -> list:
"""
Genera incrustaciones para el texto de entrada utilizando el modelo de incrustación de Google Vertex AI.
Devuelve None si el texto está vacío o se produce un error.
"""
if not text or not text.strip():
print("El texto de entrada está vacío. Se omite.")
return Ninguno
probar:
model = TextEmbeddingModel.from_pretrained(model_id)
vector = model.get_embeddings([text]) # Eliminados 'task_type' y 'output_dimensionality'
return vector[0].values
except ServiceUnavailable as e:
print(f "El servicio Vertex AI no está disponible: {e}")
return None
except Exception as e:
print(f "Error al generar incrustaciones: {e}")
return None
def emparejar_palabras_con_índice(palabras_clave):
"""
Empareja una lista de pares palabra clave-categoría con los artículos más cercanos en el índice Pinecone,
filtrando por metadatos si se especifica.
"""
resultados = []
para par_palabra_clave en palabras_clave:
palabra_clave = par_palabra_clave[0]
categoría = par_palabras_clave[1]
probar:
vector_palabra_clave = generar_incrustaciones(palabra_clave)
if not vector_palabra_clave:
print(f "No embedding generated for keyword '{keyword}' in category '{category}'.")
results.append({
Palabra clave: palabra clave,
Categoría: categoría,
'Puntuación de coincidencia': 'Error/Vacío',
'Título': 'Sin coincidencia',
'URL': 'N/A
})
continuar
query_results = index.query(
vector=vector_palabra_clave,
top_k=1,
include_metadata=True,
filter={"categoría": categoría}
)
if consulta_resultados['coincidencias']:
coincidencia_más_cercana = query_results['coincidencias'][0]
results.append({
Palabra clave: palabra clave,
Categoría: categoría,
'Puntuación': f"{closest_match['score']:.2f}",
'Título': closest_match['metadata'].get('title', 'N/A'),
'URL': closest_match['id']
})
else:
results.append({
'Palabra clave': palabra clave,
Categoría: category,
'Match Score': 'N/A',
'Título': 'No se ha encontrado ninguna coincidencia',
'URL': 'N/A
})
except Exception as e:
print(f "Error al procesar la palabra clave '{palabra clave}' con la categoría '{categoría}': {e}")
results.append({
Palabra clave': palabra clave,
Categoría: categoría,
Puntuación': 'Error',
'Título': 'Se ha producido un error',
'URL': 'N/A
})
devolver resultados
# Ejemplo de uso:
keywords = [["Herramientas SEO", "Herramientas"], ["TikTok", "TikTok"], ["Consultor SEO", "SEO"]]
matches = match_keywords_to_index(palabras clave)
# Mostrar los resultados en una tabla
print(tabulate(matches, headers="keys", tablefmt="fancy_grid"))
Y verás las puntuaciones generadas:
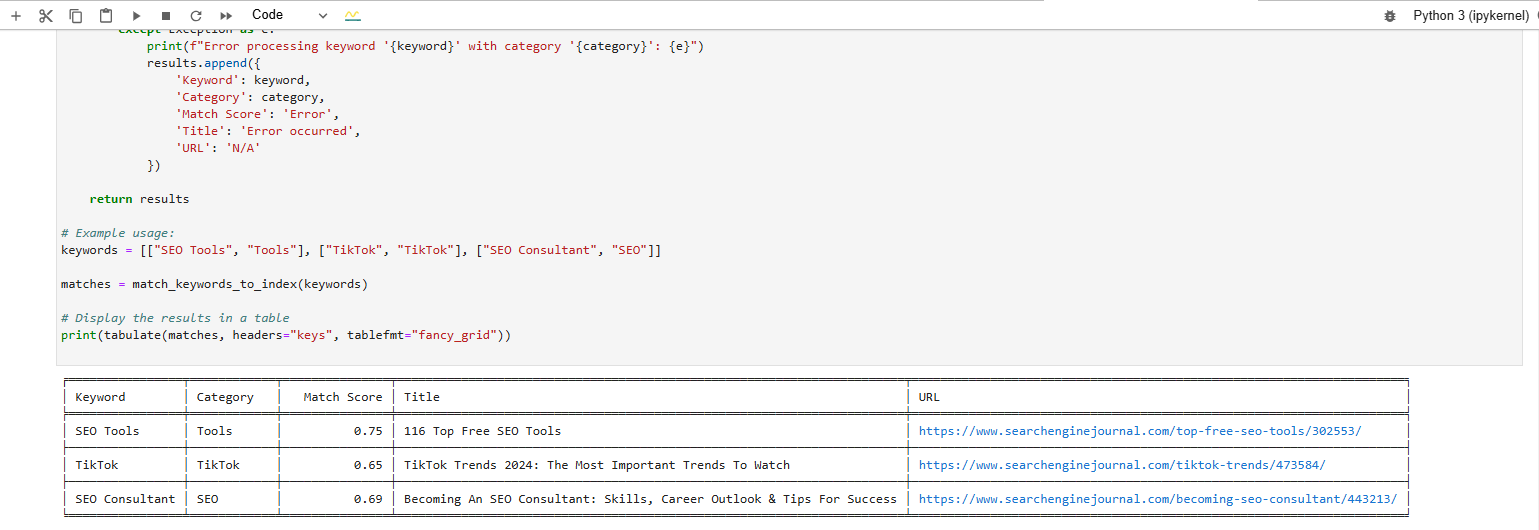 Puntuaciones de concordancia de palabras clave producidas por el modelo de integración de textos Vertex AI
Puntuaciones de concordancia de palabras clave producidas por el modelo de integración de textos Vertex AICompruebe la pertinencia de sus artículos
Se trata de una forma simplificada (amplia) de comprobar la similitud semántica de su texto con la palabra clave principal. Cree una integración vectorial de su palabra clave principal y todo el contenido del artículo utilizando Vertex AI de Google y calcular una similitud coseno.
Si el texto es demasiado largo, puede que tenga que utilizar la función estrategias de corte.
Una puntuación cercana a 1,0 (como 0,8 o 0,7). significa que estás lo suficientemente cerca sobre este tema. Si su puntuación es más baja, puede ser que una introducción demasiado larga, con muchos elementos superficiales, provoque una dilución de la relevancia y que eliminarla ayude a aumentarla.
Pero no olvide que cualquier cambio que haga debe ser juicioso desde el punto de vista de la redacción y la experiencia del usuario.
Incluso puede hacer una comparación rápida integrando el contenido mejor clasificado de un competidor y comparándose con él.
Esto le permite alinear su contenido de forma más precisa con el tema al que va dirigido, lo que puede ayudarle a posicionarse mejor.
Ya existen herramientas que realizar dichas tareaspero adquirir estos conocimientos le permitirá adoptar un enfoque personalizado adaptado a sus necesidades y, por supuesto, hacerlo de forma gratuita.
Experimentar por tu cuenta y adquirir estos conocimientos te ayudará a mantenerte a la vanguardia en lo que respecta a la IA SEO y a tomar decisiones con conocimiento de causa.
Para leer más, recomiendo estos excelentes artículos:
Más recursos :
Imagen destacada : Aozorastock/Shutterstock