Reguläre Ausdrücke (Regex) werden in der technischen Industrie auf vielfältige Weise eingesetzt. Entwickler verwenden sie, um Benutzereingaben zu validieren, und Sicherheitsoperationen nutzen sie, um Erkennungen neuer Angriffe und SIEM-Regeln zu schreiben. Eine der häufigsten Verwendungen regulärer Ausdrücke ist die Suche in großen Datenmengen oder die Bereinigung von Tool-Ergebnissen, um sie lesbarer zu machen.
Ziel dieses Artikels ist es, einen High-Level-Leitfaden für die grundlegende Formatierung von regulären Ausdrücken bereitzustellen.
Es gibt verschiedene Formen von Regex, die auf dem verwendeten Werkzeug oder der Programmiersprache basieren, und jede dieser Implementierungen kann ihre eigene nuancierte Art haben, mit bestimmten Merkmalen umzugehen. Wir werden uns nicht auf diese Situationen konzentrieren. Stattdessen konzentrieren wir uns auf einige allgemeine Gemeinsamkeiten, um uns mit der Anordnung und dem Verständnis der Art und Weise, wie Modelle angeordnet sind, vertraut zu machen. Mit diesem Verständnis wollen wir zu einem Überblick über einige der Muster übergehen, die häufig in Regex verwendet werden.
Zeichenklassen
Hierbei handelt es sich um eine Liste von Zeichen, die im Muster vorkommen können. Zwar gibt es einige unten aufgeführte "Standard"-Zeichenbereiche, doch ist es auch möglich, eine eigene Zeichenklasse zu erstellen, wenn ein Muster nur einen kleinen Satz bestimmter Zeichen verwendet. Zeichenklassen werden durch eckige Klammern um die Zeichenliste definiert :
- [a-z] - Alle Kleinbuchstaben
- [A-Z] - Alle Großbuchstaben
- [0-9] - Alle Zahlen
- [aeiou] - Benutzerdefinierte Liste individueller Merkmale, die verglichen werden sollen
- [^0–9] - Negative Übereinstimmung - jedes Zeichen, das nicht in der Liste enthalten ist
Vorkommen
Häufig wiederholt sich ein Muster, wie im Beispiel einer IP-Adresse. Diese Operatoren werden verwendet, um zu bestimmen, wie oft sich das Muster wiederholen soll :
- {1,3} - Einen Bereich festlegen - die erste Zahl ist der Mindestwert, die zweite der Höchstwert.
- {4} - Anzahl der Male, die der Grund überprüft werden muss
- + - Entspricht einem (1) oder mehreren der angegebenen Gründe
- * - Entspricht null (0) oder mehr des angegebenen Musters
- ? - Entspricht (0)null oder einer (1) des angegebenen Musters
Escape-Character
Die Verwendung von Escape-Zeichen ist ein Element in Regex-Vorlagen, das Verwirrung stiften kann. In jedem Abschnitt werden bestimmte Zeichen auf sehr spezielle Weise verwendet, z. B. eckige Klammern, um eine Liste zu definieren. Es kommt vor, dass diese Sonderzeichen auch in Ihrer Vorlage vorkommen. Damit diese Zeichen in einer Vorlage übereinstimmen, muss ein Backslash (\) als Präfix hinzugefügt werden:
- [0-9\+] - Das Muster kann 0-9 oder ein literales + enthalten.
Metazeichen
Metazeichen haben in regulären Ausdrücken eine besondere Bedeutung. So beginnen viele von ihnen mit einem Escape-Zeichen. In den meisten dieser Fälle handelt es sich um eine verkürzte Art, eine Zeichenklasse zu implementieren, um die Muster etwas prägnanter zu gestalten :
- . (Punkt) - Entspricht einem beliebigen Zeichen außer der neuen Zeile
- \d - Entspricht einer beliebigen Zahl
- \D - Entspricht jedem Zeichen außer einer Zahl
- \s - Entspricht einem beliebigen Leerzeichen
- Es gibt mehrere Leerzeichen [\/arry].
- \S - Entspricht jedem Zeichen außer einem Weißraum
- ^ - Beginn der Zeile
- $ - Ende der Zeile
Die Einrichtung
Mithilfe von regulären Ausdrücken können große Mengen an Informationen durchsucht werden, wie zum Beispiel grep auf der Befehlszeile. Im ersten Beispiel möchte ich mit grep die Ausgabe meines Befehls filtern, um nur die IP-Adressen zu erhalten, die in einem Dokument enthalten sind. Dazu müssen wir zunächst das Schema einer IP-Adresse verstehen :
- Es gibt vier (4) Sätze von Zahlen, die als Bytes bezeichnet werden und von 0 bis 255 reichen können.
- Jedes Byte wird durch einen Punkt getrennt.
Es gibt viele Möglichkeiten, dieses Muster in regulären Ausdrücken darzustellen. Hier ist eine (1) einzige mögliche Art, dieses Muster darzustellen:
|
[1-2]?[0-9]{1,2}\.[1-2]?[0-9]{1,2}\.[1-2]?[0-9]{1,2}\.[1-2]?[0-9]{1,2} |
[1-2]?–Die erste Ganzzahl des Bytes wird eine 1, 2 oder kann auch nicht aus drei (3) Ziffern bestehen.[0-9]{1,2}- Ansehen für eine Ziffer von 0 bis 9; es kann eine (1) oder zwei (2) Ziffern geben\.- Tie Verzögerung zwischen den Bytes
Beachten Sie, dass für den Punkt ein Escape-Zeichen verwendet wurde. Andernfalls würde es als das Metazeichen interpretiert werden und könnte zu falschen Ergebnissen führen. Die Suche nach Zahlen wird noch drei (3) weitere Male wiederholt, und zwar für jedes der verbleibenden Bytes. In Abbildung 1 sehen Sie einen Befehl zum Lesen einer Datei von der Linux-Befehlszeile. Die Ausgabe dieses Befehls wird an grep weitergeleitet, um die Ausgabe zu filtern, bis nur noch die Informationen vorhanden sind, die dem regulären Ausdruck (regex) entsprechen..
Wenn wir uns die Ausgabe des Befehls ansehen, stellen wir fest, dass es mehr Informationen gibt als erwartet. Dies ist eine ideale Gelegenheit, um zu betonen, wie spezifisch ein regulärer Ausdruck sein muss. In diesem Fall entspricht das Muster auch einer Versionsnummer in der Ausgabe. Indem man den regulären Ausdruck spezifischer für eine IPv4-Adresse macht, kann man die überschüssige Information eliminieren. Wenn man jedoch mit einem Muster zu genau ist, besteht die Gefahr, dass man mehr Informationen als erwartet herausfiltert und einige Ergebnisse übersieht.
Negative Übereinstimmungen werden verwendet, um nach Werten zu suchen, die nicht zu einem bestimmten Muster passen. Im folgenden Screenshot habe ich eine JSON-Datei mit einer Liste von Dinosauriern und Attributen. Da die Datei im JSON-Format vorliegt, enthält sie mehrere Sonderzeichen und ungewollte Leerzeichen. Die Verwendung einer Regex-Suche und -Ersetzung in Visual Studio Code kann helfen, diese Informationen zu bereinigen.
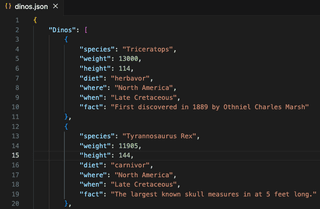
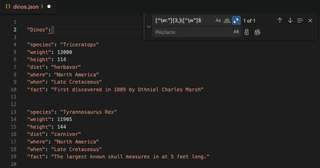
[^\w:"]- Die Suche umfasst jedes Zeichen, das kein Wort ist, und schließt Doppelpunkte und doppelte Anführungszeichen von der Suche aus, da sie Teil des Schlüssel-Wert-Paars sind.{3,}- Korrespondenz nur, wenn diese Zeichen drei (3) Mal oder öfter vorkommen; dies ist eingeschlossen, weil einige der Werte, die wir beibehalten wollen, Leerzeichen und Kommas beinhalten.|– Das Muster vor oder nach diesem Zeichen abgleichen[^w"]$- Korrespondenz jedes Zeichen außer einem Wort, mit Ausnahme von Anführungszeichen, am Ende einer Zeile
Nach dem Suchen und Ersetzen in Visual Studio Code wurde ein großer Teil der JSON-Formatierung entfernt. Dies scheint eine ausreichende Lösung für diesen Anwendungsfall zu sein.
Endlich, Regex101 ist eine hervorragende Ressource zum Testen von regulären Ausdrücken anhand von Beispielinformationen. Diese Ressource ermöglicht es den Nutzern außerdem, den Regex-Typ bzw. die Programmiersprache, mit der sie arbeiten, auszuwählen, um bestimmte sprachspezifische Token zu verwalten..
Ein weiteres sehr nützliches Werkzeug, um das Wissen über Regex-Klassen zu vertiefen, ist https://regexcrossword.com/. Die Seite verwendet rationale Ausdrücke in einem Kreuzworträtselgitter, damit die Nutzer die Lösung finden.