Las expresiones regulares (regexes) se utilizan de diversas maneras en las industrias técnicas. Los desarrolladores las utilizan para validar las entradas de los usuarios, y las operaciones de seguridad las emplean para escribir nuevas detecciones de ataques y reglas SIEM. Uno de los usos más comunes de las expresiones regulares es buscar en grandes cantidades de datos o limpiar los resultados de las herramientas para hacerlos más legibles.
El objetivo de este artículo es proporcionar una guía de alto nivel sobre el formateo básico de expresiones regulares.
Existen diferentes formas de regex basadas en la herramienta o lenguaje de programación utilizado, y cada una de estas implementaciones puede tener su propia forma matizada de manejar características específicas. No nos centraremos en estas situaciones. En su lugar, nos centraremos en algunos aspectos comunes generales para familiarizarnos con la disposición y la comprensión de cómo se disponen los modelos. Con esta comprensión, pasemos a una visión general de algunos de los patrones que se utilizan comúnmente en regexes.
Clases de personajes
Se trata de una lista de caracteres que pueden aparecer en el patrón. Aunque hay algunos rangos "estándar" listados a continuación, también es posible crear una clase de caracteres personalizada cuando un patrón utiliza sólo un pequeño conjunto de caracteres específicos. Las clases de caracteres se definen mediante corchetes alrededor de la lista de caracteres:
- [a-z] - Todas las minúsculas
- [A-Z] - Todo en mayúsculas
- [0-9] - Todas las cifras
- [aeiou] - Lista personalizada de caracteres individuales para comparar
- [^0–9] - Coincidencia negativa - cualquier carácter no incluido en la lista
Ocurrencias
Un patrón se repite a menudo, como en el ejemplo de una dirección IP. Estos operadores se utilizan para determinar cuántas veces debe repetirse el patrón:
- {1,3} - Defina un intervalo: el primer dígito es el valor mínimo y el segundo, el máximo.
- {4} - Número de veces que debe comprobarse el motivo
- + - Corresponde a uno (1) o más de los motivos especificados
- * - Corresponde a cero (0) o más del patrón especificado
- ? - Corresponde a (0)cero o uno (1) del patrón especificado
Caracteres de escape
El uso de caracteres de escape es un elemento de las plantillas regex que puede llevar a confusión. En cada sección, ciertos caracteres se utilizan de formas muy específicas, como los corchetes para definir una lista. A veces, estos caracteres especiales aparecen en su plantilla. Para que estos caracteres coincidan en una plantilla, debe añadirse una barra invertida como prefijo:
- [0-9\+] - El patrón puede contener 0-9 o un + literal.
Metapersonajes
Los metacaracteres tienen un significado especial en las expresiones regulares. Por ejemplo, muchas de ellas comienzan con un carácter de escape. En la mayoría de los casos, se trata de una forma abreviada de implementar una clase de caracteres para que los patrones sean un poco más concisos:
- . (punto) - Corresponde a cualquier carácter excepto la nueva línea
- \d - Corresponde a cualquier número
- \D - Corresponde a cualquier carácter que no sea un dígito
- \s - Corresponde a cualquier carácter de espacio
- Hay varios caracteres de espaciado [\n\r\t\f].
- \S - Corresponde a cualquier carácter que no sea un espacio en blanco
- ^ - Inicio de línea
- $ - Fin de línea
Puesta en marcha
Las expresiones regulares se pueden utilizar para buscar grandes cantidades de información, como grep en la línea de comandos. En el primer ejemplo, quiero utilizar grep para filtrar la salida de mi comando y obtener sólo las direcciones IP contenidas en un documento. Para ello, primero tenemos que entender el esquema de una dirección IP:
- Hay cuatro (4) conjuntos de números, llamados bytes, que pueden ir de 0 a 255.
- Cada byte está separado por un punto.
Hay muchas formas de representar este patrón en expresiones regulares. Aquí hay sólo una (1) forma posible de representar este patrón:
|
[1-2]?[0-9]{1,2}\.[1-2]?[0-9]{1,2}\.[1-2]?[0-9]{1,2}\.[1-2]?[0-9]{1,2} |
[1-2]?–El primer entero del byte será un 1, 2, o puede no constar de tres (3) dígitos.[0-9]{1,2}- Ver para un dígito de 0 a 9; puede haber uno (1) o dos (2) dígitos\.- Tl retardo entre bytes
Tenga en cuenta que se ha utilizado un carácter de escape para el punto. De lo contrario, se interpretaría como el metacarácter y podría dar resultados incorrectos. La búsqueda de dígitos se repite tres (3) veces más, para cada uno de los bytes restantes. La figura 1 muestra un comando para leer un fichero desde la línea de comandos de Linux. La salida de este comando se pasará a grep para filtrar la salida hasta que sólo esté presente la información que coincida con la expresión regular (regex)..
Si observa la salida del comando, verá que hay más información de la esperada. Esta es una oportunidad ideal para enfatizar lo específica que debe ser una expresión regular. En este caso, el patrón también corresponde a un número de versión en la salida. Haciendo la expresión regular más específica para una dirección IPv4, es posible eliminar el exceso de información. Sin embargo, si se es demasiado específico con un patrón, se corre el riesgo de filtrar más información de la debida y perder algunos resultados.
Las coincidencias negativas se utilizan para buscar valores que no coinciden con un modelo determinado. En la siguiente captura de pantalla, tengo un archivo JSON que contiene una lista de dinosaurios y atributos. Como el archivo está en formato JSON, contiene una serie de caracteres especiales y espacios no deseados. El uso de regex search and replace en Visual Studio Code puede ayudar a limpiar esta información.
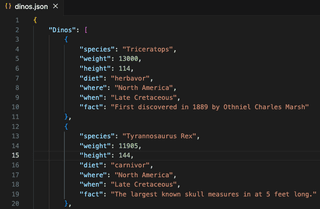
[^\w:"]- La búsqueda busca cualquier carácter que no sea una palabra, y excluye de la búsqueda los dos puntos y las comillas dobles, ya que forman parte del par clave-valor.{3,}- Correspondencia sólo si estos caracteres aparecen tres (3) veces o más; esto se incluye porque algunos de los valores que queremos conservar incluyen espacios y comas.|– Coincide con el patrón antes o después de este carácter[^\w"]$- Correspondencia cualquier carácter que no sea una palabra, a excepción de las comillas, al final de una línea
Tras realizar la búsqueda y sustitución en Visual Studio Code, se eliminó gran parte del formato JSON. Esta parece ser una solución suficiente para este caso de uso.
Y finalmente.., Regex101 es un excelente recurso para probar expresiones regulares con información de ejemplo. Este recurso también permite a los usuarios elegir el tipo de regex, o lenguaje de programación, con el que están trabajando, con el fin de manejar ciertos tokens específicos del lenguaje..
Otra herramienta muy útil para reforzar tus conocimientos sobre las clases regex es https://regexcrossword.com/. El sitio utiliza expresiones racionales en una cuadrícula de crucigrama para ayudar a los usuarios a encontrar la solución.