Il n’a fallu que vingt-quatre heures après la publication de Gemini pour que quelqu’un remarque que les chats étaient affichés publiquement dans les résultats de recherche de Google. Google a rapidement réagi à ce qui semblait être une fuite. La raison pour laquelle cela s’est produit est assez surprenante et pas aussi sinistre qu’il n’y paraît à première vue.
@shemiadhikarath tweeté:
« Quelques heures après le lancement de @Google Gemini, des moteurs de recherche comme Bing ont indexé les conversations publiques de Gemini. »
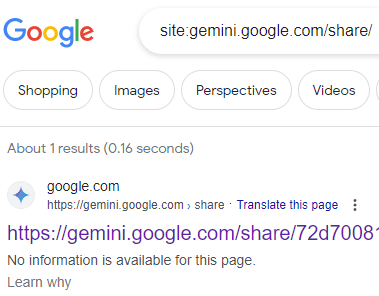
Ils ont publié une capture d’écran de la recherche sur le site de gemini.google.com/share/
Mais si vous regardez la capture d’écran, vous verrez qu’il y a un message qui dit : « Nous aimerions vous montrer une description ici mais le site ne nous le permet pas ».
Tôt dans la matinée du mardi 13 février, les chats Google Gemini ont commencé à disparaître des résultats de recherche de Google, qui n’affichait plus que trois résultats. Dans l’après-midi, le nombre de chats Gemini ayant fait l’objet d’une fuite et apparaissant dans les résultats de recherche s’est réduit à un seul résultat.
Comment les pages du chat Gemini ont-elles été créées ?
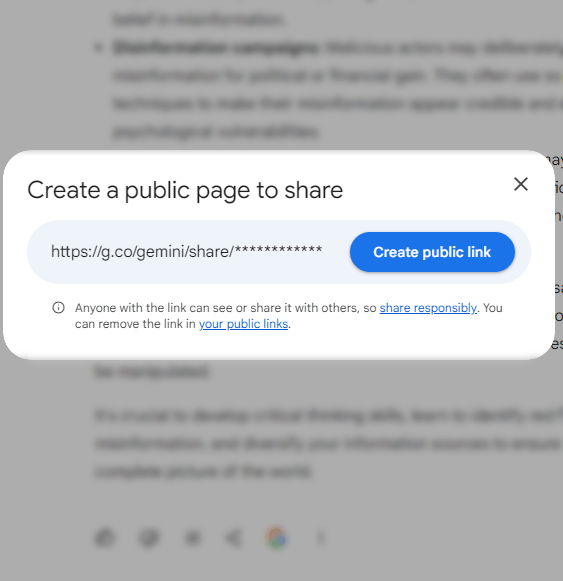
Gemini permet de créer un lien vers une version publique d’une discussion privée.
Google ne crée pas automatiquement de pages web à partir des discussions privées. Les utilisateurs créent les pages de chat à l’aide d’un lien situé au bas de chaque chat.
Capture d’écran de la création d’une page de discussion partagée
Pourquoi les pages du chat Gemini ont-elles été indexées ?
La raison évidente pour laquelle les pages de chat ont été explorées et indexées est que Google a oublié de placer un fichier robots.txt à la racine du sous-domaine Gemini (gemini.google.com).
Un fichier robots.txt est un document permettant de contrôler l’activité des robots d’indexation sur les sites web. Un éditeur peut bloquer des robots spécifiques en utilisant les commandes normalisées dans le protocole Robots.txt.
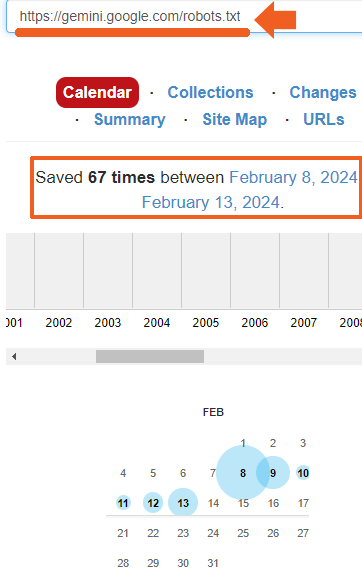
J’ai vérifié le fichier robots.txt à 4h19 du matin le 13 février et j’ai vu qu’il y en avait un en place :

J’ai ensuite consulté Internet Archive pour voir depuis combien de temps le fichier robots.txt était en place et j’ai découvert qu’il y était depuis au moins le 8 février, le jour où les applications Gemini ont été annoncées.
Capture d’écran d’Internet Archive
Cela signifie que la raison évidente pour laquelle les pages de discussion ont été explorées n’est pas la bonne, c’est simplement la raison la plus évidente.
Bien que le sous-domaine Google Gemini ait un fichier robots.txt qui bloque les robots d’exploration de Bing et de Google, comment ces derniers ont-ils pu explorer ces pages et les indexer ?
Deux façons de découvrir et d’indexer des pages de chat privées
- Il existe peut-être un lien public quelque part.
- Il est moins probable, mais peut-être possible, qu’ils aient été découverts grâce à l’historique de navigation lié aux cookies.
Il est plus probable qu’il existe un lien public.
J’ai demandé à Bill Hartzer (@bhartzer) à ce sujet et il a découvert un lien public pour l’une des pages indexées :
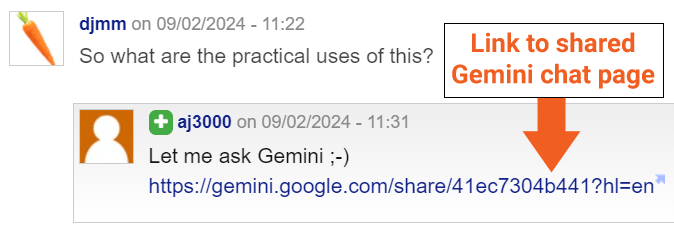
Nous savons donc maintenant qu’il est très probable qu’un lien public soit à l’origine de l’exploration et de l’indexation de ces pages de chat Gemini.
Bill Hartzer a fait cette observation :
« Même si l’URL de Gemini est bloquée dans le fichier robots.txt, il y a un lien vers l’URL de Gemini dans un commentaire de blog, de sorte que l’URL de Gemini est indexée.
Cela prouve que Google indexe toujours les URL dont l’exploration est bloquée dans le fichier robots.txt.
Si Google voulait vraiment s’assurer que l’URL Gemini n’est pas indexée, il autoriserait l’exploration dans le fichier robots.txt et ajouterait une balise méta noindex sur les pages. Peut-être Google devrait-il suivre ses propres conseils ? »
Pourquoi les pages de chat ont-elles commencé à disparaître des résultats de recherche ?
Mais s’il existe un lien public, pourquoi Google a-t-il commencé à supprimer les pages de discussion ? Google a-t-il créé une règle interne pour le robot de recherche afin d’exclure les pages web du dossier /share/ de l’index de recherche, même si elles sont publiquement liées ?
Aperçu de la manière dont Bing et Google Search indexent les contenus
Voici maintenant la partie vraiment intéressante pour tous les geeks intéressés par la façon dont Google et Bing indexent le contenu.
L’index de recherche de Microsoft Bing a réagi au contenu de Gemini différemment de celui de Google. Alors que Google affichait encore trois résultats de recherche au petit matin du 13 février, Bing n’affichait qu’un seul résultat provenant du sous-domaine. La qualité de ce qui était indexé et sa quantité semblaient aléatoires.
Pourquoi les pages de chat de Gemini ont-elles fuité ?
Voici les faits connus :
- Google a mis en place un fichier robots.txt depuis le 8 février.
- Google et Bing ont tous deux indexé les pages du sous-domaine gemini.google.com.
- Il est possible que Google et Bing aient découvert des liens vers les chats et les aient ensuite indexés.
- Les moteurs de recherche ont indexé le contenu sans tenir compte du fichier robots.txt et ont ensuite commencé à le rejeter.
Cela nous ramène à la question de savoir pourquoi ces pages ont commencé à disparaître des résultats de recherche de Google et de Bing. À mon avis, les pages de chat de Google Gemini sont des pages web de faible qualité qui ne valent pas la peine d’être affichées pour ce qui est essentiellement des recherches de longue haleine (site:gemini.google.com/share/). Il n’y a vraiment aucune raison utile de faire apparaître ces pages dans les résultats de recherche.
Le contenu bloqué par Robots.txt peut toujours être découvert, exploré et figurer dans l’index de recherche. Si les pages sont utiles, elles peuvent également être classées, à moins qu’elles ne soient pas utiles. Je pense que c’est le cas.